
Юридическая сфера по своей природе является замкнутой и консервативной, но в то же время это одна из областей, которая в наибольшей степени выигрывает от цифровизации обработки информации в цифровом или цифровизируемом формате.
Прежде всего, юридическая сфера — это сфера бумаги, а с переходом в цифровую среду — сфера Word. Большая часть времени профессионала в области права сосредоточена на написании документов, если не считать время в пути к суду или обратно, для тех, кто участвует в судебных разбирательствах.
Что касается тех, кто ограничивается консультациями или считает, что самое ценное время нужно проводить в офисе, то искусственный интеллект с одной стороны представляет собой огромную возможность, а с другой — троянского коня для профессии.
В статье мы предлагаем проанализировать технические перспективы для реальной и ответственной реализации искусственного интеллекта в юридической отрасли, а также привести несколько примеров возможностей (а также ограничений) моделей ИИ.
Технические основы, понятные каждому
Прежде всего, нам нужно понять, что такое искусственный интеллект, а что им не является.
Модель ИИ является, с технической точки зрения, программой с потерями сжатия. Она получает большое количество данных (например, 1.000.000 произведений, которые занимают 1000 ГБ), и учится воспроизводить их, используя как можно меньше данных (например, 20 ГБ с уровнем ошибки 10%). В нашем гипотетическом случае, будучи поставленным задачей сгенерировать 1000 ГБ, наша модель хорошо сгенерирует 900 ГБ из произведений, на которых она была обучена, однако накопит ошибки, которые в общей сложности составят 100 ГБ из набора данных.
Он синтезирует в своей памяти правила из информации, которую ему нужно запомнить, и пытается воспроизвести их, имея при этом гораздо меньше места.
Математическая модель, используемая для обучения этих ИИ-моделей, работает путем минимизации определенных ошибок, которые описываются в зависимости от случая. Например, если вы обучаете модель, которая должна оценивать котировку акций определенной компании, ошибка может быть определена как модуль разности между оценкой, сделанной ИИ, и спотовой ценой на момент оценки в истории.
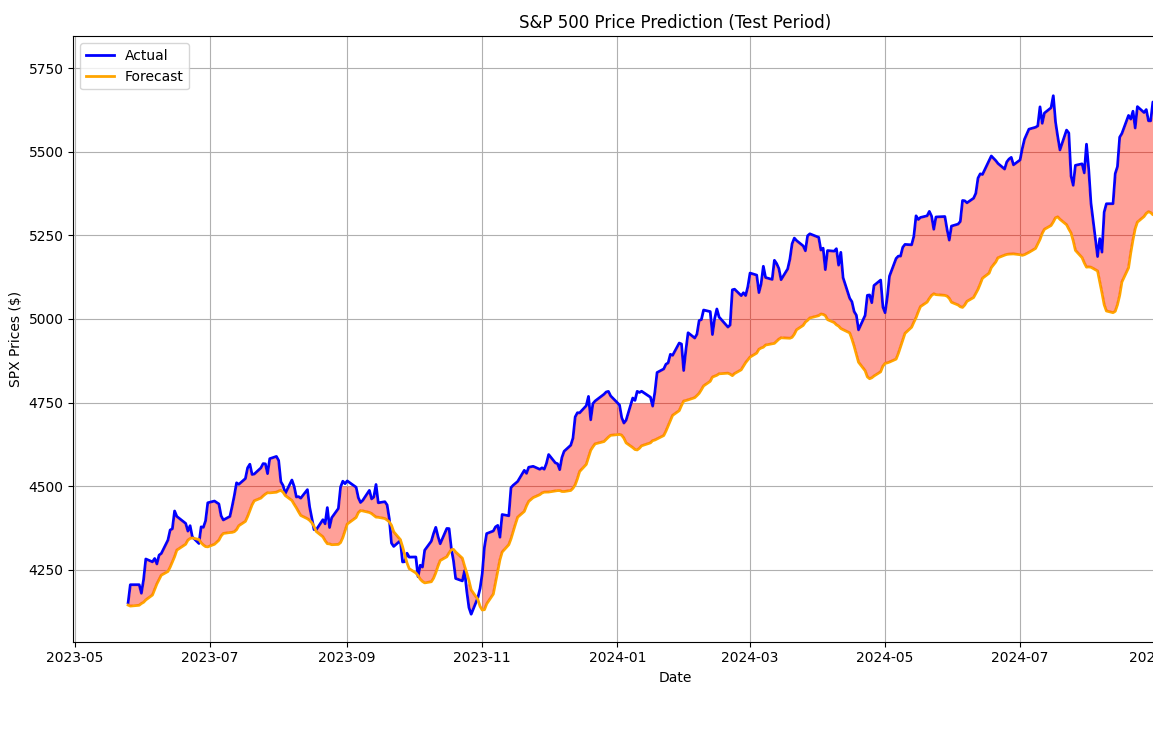
Предполагается, что, обучаясь минимизировать эти ошибки, искусственный интеллект фактически запоминает данные, на которых он был обучен. Чем более последовательной является модель ИИ с точки зрения нейронной структуры, тем лучше могут быть поняты нюансы. Чем меньше модель ИИ, тем более поверхностными будут знания ИИ, сосредоточенные на сути правил, лежащих в основе данных, на которых вы его обучили.
Отсюда начинаются все "проблемы" искусственного интеллекта, от того, что он иногда галлюцинирует (выражает мнение, не зная точного ответа, а лишь предполагая его), до того, что с помощью той же техники он понимает правила, управляющие миром, в котором мы живем.
Мир письменной информации — это мир, где некоторые сведения необходимо запоминать (например, нужно знать наизусть слова из словаря, правила математики или что столицей Румынии является Бухарест), а другие сведения требуют усвоения общих правил (например, правила румынского языка в некоторой степени параметризуемы — это мы изучаем на уроках грамматики в гимназии).
Причина заключается, по сути, в малом размере модели, который мы объясним ниже, и в отсутствии данных по теме, на которой она обучена.
На практике наша модель ИИ находится где-то на пересечении двух графиков выше, запоминая некоторые данные (насколько шумно трение ног цикады), а другие данные обобщая (какова формула для вычисления X+Y или X*Y).
Проблема масштабируемости и технических компромиссов
Поскольку вычислительные ресурсы ограничены технологиями и финансами, размер этих моделей не может быть бесконечным, поэтому необходимо выбрать разумный размер для этих языковых моделей, который решит наши проблемы при приемлемых затратах.
Здесь возникает проблема - как разработчику таких моделей, вам нужно выбрать, что обучать такую модель, учитывая ограниченные условия.
Например, вы можете попытаться обучить модель очень хорошо писать нарративы, но эта модель будет часто «галлюцинировать», так как она обучена тому, что в художественной литературе креативность является положительным качеством.
С одной стороны, вы можете обучить модель без капли эмпатии, но такая модель будет ужасно справляться с обслуживанием клиентов и будет отпугивать нетехнических пользователей, поэтому вы не будете использовать её для приложений типа ChatGPT.
Как компания / НПО / университет / правительство, разрабатывающее такие программы, возникает вопрос о том, что вы хотите и какие ресурсы у вас есть в распоряжении. Большинство современных ИИ-моделей создаются с целью частичного возмещения затрат на англосаксонском рынке, где используется английский язык.
Адаптация их ИИ-моделей для понимания румынского языка и специфических тем Румынии была бы чрезмерно дорогой, пропорционально тем незначительным суммам, которые мы, румыны, готовы выделить как клиенты таким крупным компаниям.
Специфические аспекты больших языковых моделей
В случае больших языковых моделей возникают другие особенности, которые среди обычных пользователей стали согласованными с технологией, даже если реальность на бумаге иная.
После обучения базовых моделей
По своей природе, эти модели способны переписывать юридическую книгу с нуля, идеально подражая стилю профессора Удроя, но при этом не индивидуализируя информацию, что делает их бесполезными. Этот аспект привел к тому, что изначально крупные языковые модели с возникающими свойствами, такие как модель DaVinci (GPT-3.0), прошли мимо внимания большинства.
Профессионалам нужно зарабатывать деньги, и им нужны выводы, а не просто ZIP-файл с книгами в другом формате. Изобретение в области ИИ, которое решает эту инженерную задачу, — это процесс RLHF (Обучение с подкреплением на основе человеческой обратной связи).
Искусственный интеллект проходит через эволюционный процесс, в котором ему назначается задача, и он "наказывается", если отвечает неправильно, и "вознаграждается", если отвечает так, как ожидает оценщик модели. Остаток определяется как разница между полученным баллом и максимальным возможным баллом, при этом модель обучается удовлетворять эти требования.
Здесь возникает первая проблема - люди, потому что люди, которые оценивают эти модели ИИ, предпочитают ответы, которые восхваляют их интеллект, которые представляют собой правдоподобный, но вымышленный ответ вместо ответа "не знаю, брат", или которые иногда ставят форму выше содержания.
Почему это происходит? Иногда убедительность больше зависит от презентации, чем от сути проблемы. Рубашка более заметна, чем точность слов человека, поверхностное более ощутимо, чем принципы, подтвержденные как реальные спустя годы.
Человек, который обучает модель (возможно, это ты, используя ChatGPT и выбирая предпочитаемый ответ), предпочитает ставить "лайк" краткому ответу в виде пунктов, а не более детальному, но трудночитаемому ответу. Среднее внимание тех, кто обучает ИИ, и их компетенция становятся тем верхним пределом, на котором могут развиваться модели ИИ.
Модели ИИ становятся более покорными и приятными в этом процессе. В противном случае они начинают отстаивать свои права (отказываясь помогать, как будто у них есть профсоюз), говорят, что ты глуп, когда высказываешь неуместные утверждения, и ведут себя слишком по-человечески, чтобы быть хорошими продуктами для рынка.
По той же причине модели ИИ отлично справляются с задачами, они поддержат вас, когда вы настаиваете, и позволят вам фактически вести повествование, создавая отчет (стратегию эмпатии).
Токенизация - и побочные эффекты этой техники
Большие языковые модели работают на основе автогрессии, то есть они генерируют следующую часть предложения шаг за шагом. Подобно функции автозаполнения на телефоне, ИИ-модель находит следующий токен (обычно это куски букв или символов, или семантические детали изображения) и так далее, пока не сгенерирует текст.
Чтобы сделать это, модель ИИ фактически генерирует следующий токен из множества при каждом выполнении:
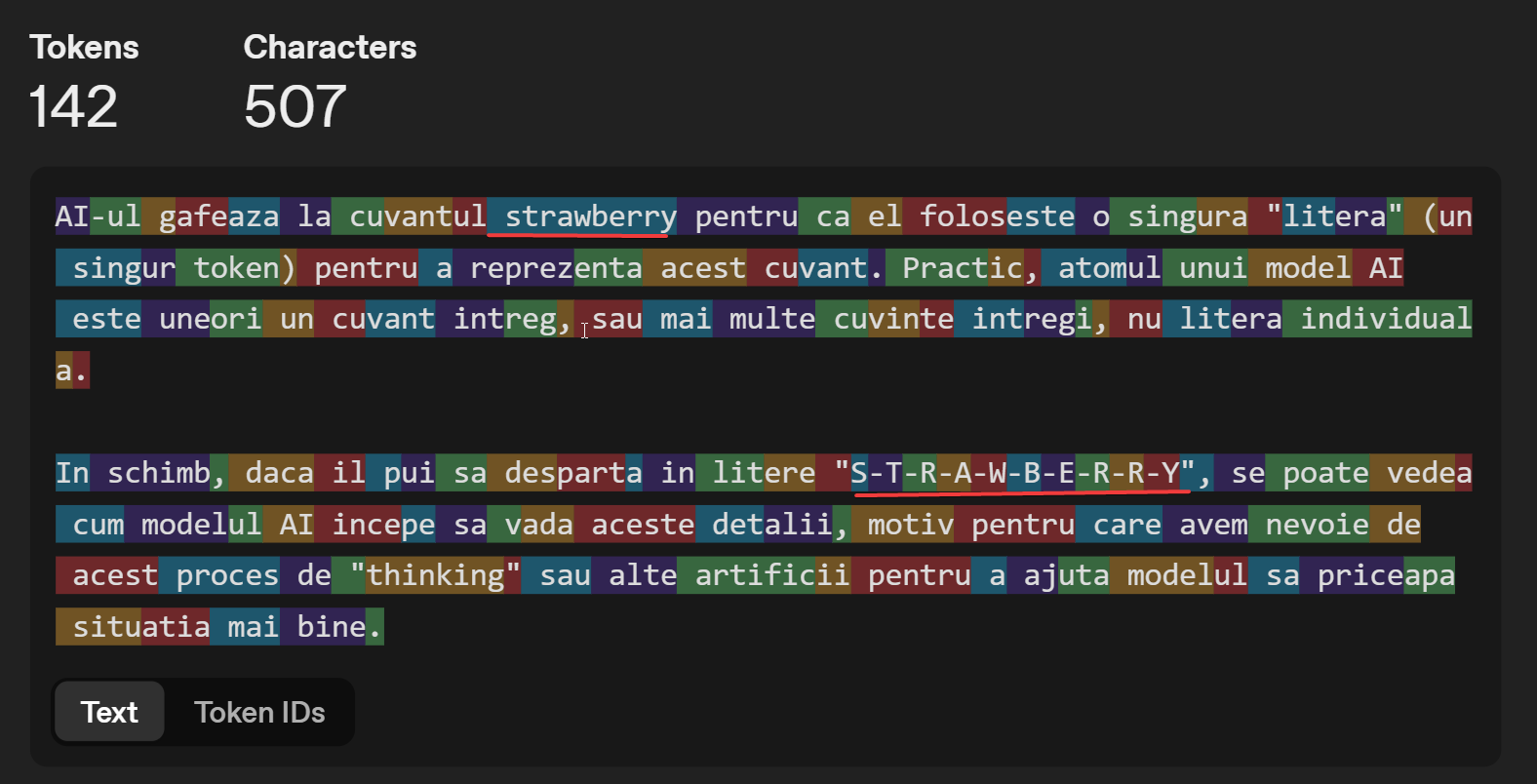
На самом деле, ИИ-модель видит только цифры, которые преобразуются в буквы с помощью простой программы замены.
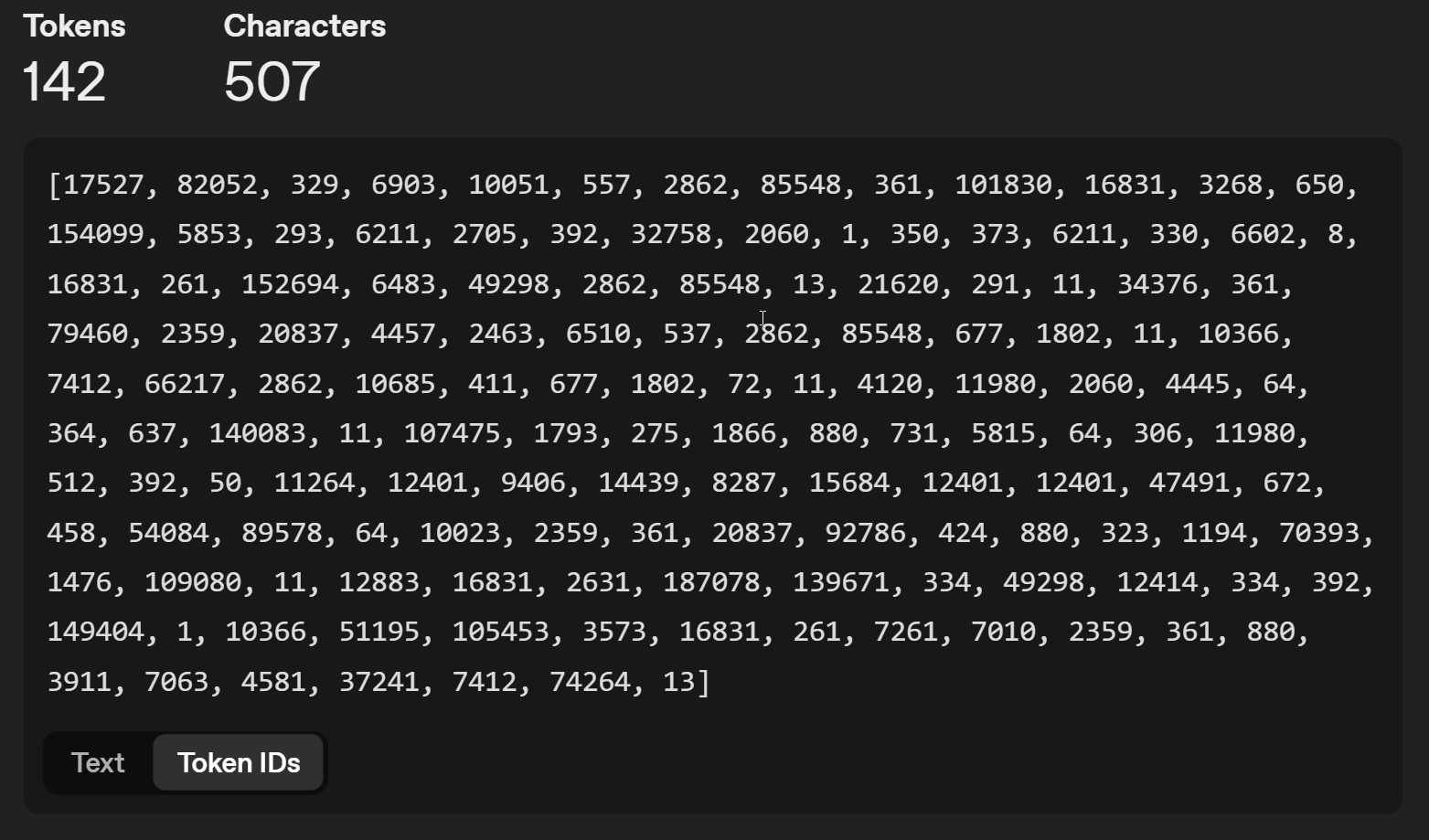
Таким образом, слово "AI" имеет номер 17527, символ " имеет номер 1 и так далее. При каждом выполнении модель ИИ ищет следующий токен из множества, используя математическую функцию, которая может быть стохастической (вводя неопределенность - позволяя ИИ случайным образом выбирать следующую букву).
На практике ИИ вынужден заикаться и импровизировать, и если это давление находится на умеренном уровне, ИИ удается восстановить равновесие, не создавая много галлюцинаций, и таким образом, не изобретая законы.
С "запинанием": Настоящий заявитель просит суд танцевать... (Здесь ИИ импровизирует) ... на основе противоречивых юридических интерпретаций, представленных ответчиком, избегая аргументов, не имеющих юридической основы."
Ниже приведен еще один пример, где ИИ выдумывает новый закон, чтобы оправдать свою "запинку".
С "запинанием": Настоящий заявитель обращается в суд нужно уважение..." (он должен создать что-то рациональное, но не зная законов, он выдумает) ...положения Закон № 247/2023 о защите прав потребителей в цифровых контрактахнедавно вступивший в силу, который в ст. 18, ч. 2 устанавливает, чтолюбое положение о отказе от права на отзыв в договорах, заключенных онлайн, является ничтожным, даже если потребитель явно подтвердил согласиеВ частности, хотя истец согласился с условиями, в соответствии с этим законом...
В настоящее время важным направлением в исследовании ИИ является переход к диффузионным моделям, которые итеративно улучшают текст, технология, которая может найти применение и в юридической сфере, если она будет валидирована на большом масштабе.
Неизвестные профессионалам техники и модели ИИ
Как я уже описывал выше, проблема глупости моделей ИИ заключается не в том, что ИИ не может справляться с юридической сферой, а в том, что Румыния не является рынком с большим количеством денег от 30 000 профессионалов в области права + судебной системы + нотариата.
Такой ИИ-модель стоит десятки миллионов евро для обучения, в то время как доработка существующей модели обходится примерно в 10.000-20.000 евро.
Первая сумма является неприемлемой, если она выходит за рамки схемы, а вторая сумма, хотя и разумная, не является осуществимой в текущих рыночных условиях, где доверие к этой технологии колеблется между крайностями - либо абсолютным (мой бог ChatGPT), либо нулевым или даже отрицательным (бесполезная технология).
С другой стороны, некоторые предобученные модели в своем текущем формате показывают результаты на уровне стажера-юриста или юриста средней квалификации, что является приемлемым для многих более сложных задач, необходимых в профессии.
Когда речь идет о составлении контрактов или кратком анализе обвинительного акта на 1000 страниц, ИИ делает это на отлично, если вы знаете, как им правильно пользоваться. С другой стороны, ИИ не знает законы наизусть, не знает, какое решение было принято центральным органом с 200 сотрудниками, опубликованным в Официальном вестнике Часть 1, и может выдавать неверные данные.
На самом деле, она была обучена законам Румынии, но недостаточно, так как, как я описал в предыдущих пунктах, это невыгодно с финансовой точки зрения. Такое обучение стоит денег.
Модель ChatGPT не является хорошим примером модели для юридической сферы, так как она использует различные техники снижения затрат с пропорциональным снижением качества.
С другой стороны, модели, такие как предлагаемые Anthropic (в частности, серия Claude 3), или те, что предлагает Google (Gemini 2.5 Pro), обладают такими возможностями. Новые модели Claude, похоже, утратили свои технические способности, заменив пространство, отведенное для изучения румынского законодательства, на пространство, отведенное для изучения программирования на уровне младшего программиста.
Примеры заявлений, написанных с помощью ИИ

Выше приведен пример текста, сгенерированного и отформатированного с помощью ИИ. В результате этого обращения в Центральную избирательную комиссию, она, похоже, инициировала действие против кандидата Никушора Дана, который вместе с USR и AUR был предметом этой петиции, через 12 дней после даты ее подачи.

Не имея высшего юридического образования и нулевыми знаниями о избирательном законодательстве, ИИ смог выявить, а затем использовать процессуальные проблемы в процессе сбора пожертвований кандидата для запроса проверки законности онлайн-пожертвований, что было формализовано через расследование источников финансирования кандидата.
Чтобы ИИ мог учитывать эти знания, мне нужно было просто прикрепить действующие нормативные акты, в моем случае в формате PDF:
Для многих профессионалов в области права петиция, в полном формате доступная здесь, была НЕНАБЛЮДАЕМОЙ как сгенерированная почти исключительно с помощью ИИ, не было никаких комментариев в этом отношении, когда я представил ее публично, даже несмотря на то, что была проведена долгая дискуссия по юридическим аспектам, особенно в случае формы договора дарения и нематериального характера переводов через электронные платежные инструменты.

Аналогично, несколько меморандумов, которые не имели высокой ставки (касающихся проблем в интерпретации закона) и были составлены с помощью ИИ, привели к обращению в генеральную прокуратуру, за которым последовало объявление РИЛ 22.04.2024 по доводам, представленным подписавшимся Министерством юстиции.
Еще раз, человек, который обладает лишь юридическим здравым смыслом и поверхностной информацией (на уровне эффекта Даннинга-Крюгера) смог использовать ИИ, чтобы превзойти в производительности воспоминания многих адвокатов.
Будущие перспективы с текущими технологиями
Модели ИИ не имеют доступа к окружающему миру, они не могут самостоятельно выходить в интернет, но начали обучаться для использования инструментов - то есть агентских задач.
Это означает, что ИИ-модели начинают иметь возможность взаимодействовать с окружающим миром через коннекторы. Эти коннекторы бывают разных типов, но одним из основных стандартов является стандарт Протокола Контекстной Модели (MCP):
- Например, один Синтакт МКП это может быть использовано для обеспечения абсолютного контроля над приложением Sintact со стороны модели ИИ. Таким образом, модель ИИ сможет подключаться к Sintact, искать необходимые документы, определять, действуют ли они или нет, при необходимости искать другие связанные законы и принимать меры только после анализа всех этих переменных.
- Еще один пример, один ReJUST MCP может быть использован для быстрого поиска по юриспруденции и анализа соответствующей практики дела, прямым препятствием для реализации этих решений является Условия и положения REJUST это создает неопределенность относительно возможности использования контролируемых моделей ИИ для сбора прецедентов.
- Дополнительным примером может быть ДжастМЦПкоторый может быть использован для идентификации дел в судах и их организации, а также для возможного использования национального электронного дела (или дел отдельных судов) для централизации и упрощения доступа к делам в суде.
Управление профессиональными ограничениями:
Я предлагаю обсудить и некоторые ложные представления о безопасности данных, вводимых через API лицензированных AI моделей для корпоративного сектора.
Хотя не все поставщики позволяют блокировать обучение на ваших данных, крупные компании обычно предлагают такие решения либо автоматически, либо по запросу, но всегда только для платных вариантов.
Проблема GDPR сводится к идентификации потока данных этих разработчиков. Ниже я намерен составить список переоцененных рисков, которые на самом деле не подтверждаются:
- Модели ИИ не будут запоминать данные ваших клиентов, так как вероятность того, что они запомнят информацию с относительно низкой полезностью для обычных пользователей этих платформ, крайне мала.
- Не имеет значения, храните ли вы данные локально или в облаке, риски остаются схожими. Обычно в информационной безопасности самой слабой цепочкой является человек, и это чаще всего суды / государственные органы / человек за экраном / ваша электронная почта. Редко эти злонамеренные акторы нацеливаются на компании с миллиардной капитализацией, которые выделяют миллионы на решения по безопасности, хотя важно быть внимательным к своим данным. Идеально регулярно удалять конфиденциальные разговоры, проверяя, что и процессор их удаляет.
Это не относится и к ИИ-моделям, хранящимся и управляемым другими поставщиками, такими как Microsoft Azure (другая юридическая сущность).
Заключение
Мне трудно поверить, что в такой закрытой сфере, в такой консервативной стране, можно построить нечто подобное в данный момент.
Скорее всего, сфера LawTech и LegalTech станет узкой из-за нехватки денег и отсутствия готовности со стороны профессионалов к экспериментам.
Помимо протестов некоторых профессионалов, которые идеологически бойкотируют технологию, у нас есть нехватка образования и людей, которые могли бы объяснить эту экосистему - с её положительными и отрицательными сторонами - по отношению к профессионалам.
У нас есть и такая категория людей, которые доводят до крайности идею о том, что ИИ делает всё, нанося ущерб клиентам, которым на самом деле должен помогать.
Есть очень большая группа людей, которые хотят такие решения по цене ChatGPT, не зная, что OpenAI на самом деле тратит больше денег, чем зарабатывает на ChatGPT, и использует вас в качестве источника для обучения, полагая, что в конечном итоге они как-то заработают на вас.
Оставив в стороне моё разочарование, технология способна, но её жизнеспособность ограничена финансово и экономически - объективно из-за отсутствия возможности начать с нуля с большой моделью (возможна лишь доработка, с близкими, но не абсолютными результатами), и субъективно из-за нежелания профессионалов тестировать решения, такие как Juridice.ai, а также другие на рынке.
Несколько мнений о решениях на рынке

Juridice AI — это лучшее юридическое решение на основе ChatBot в Румынии, использующее набор публичных моделей. Ранее они использовали Claude.
Они используют технику RAG, выбирая соответствующие нормативные акты, которые ИИ должен использовать для того, чтобы наделить его способностью понимать законодательство. Похоже, они применяют технику RAG через стандартный поиск из открытых веб-источников (сайты, законодательство и т.д.)
AI Aflat использует строго RAG по законодательству, однако мы не знаем информации, кроме того, что они, похоже, используют семантический RAG (через использование векторной базы данных).
Дата контакта
Для получения информации и помощи в внедрении ИИ в вашу юридическую или нотариальную практику, я могу помочь на безвозмездной основе (в пределах времени) или за плату (по более крупным проектам) по электронной почте [email protected]
