
法律领域本质上是一个封闭和保守的领域,但同时也是最能从信息处理数字化或可数字化中受益的领域之一。
首先,法律领域是一个纸质的领域——随着向数字环境的过渡,变成了Word文档。法律专业人士的大部分时间都集中在撰写文件上,排除往返法庭的时间,尤其是那些参与诉讼的人。
对于那些仅限于咨询的人,或者认为最宝贵的时间应该留在办公室的人来说,人工智能一方面是一个巨大的机会,另一方面也是对职业的一个特洛伊木马。
在本文中,我们旨在分析人工智能在法律行业的实际和负责任实施的技术前景,并提供一些关于AI模型的能力(以及局限性)的例子。
通俗易懂的技术基础
首先,我们必须理解什么是人工智能,什么不是人工智能。
一个AI模型在技术上是一个有损压缩程序。它接收大量数据(例如:1,000,000个作品,总大小为1000GB),并学习如何使用尽可能少的数据(例如:20GB,错误率为10%)来重现这些数据。在我们假设的情况下,如果要求生成1000GB,我们的模型将能够很好地生成900GB的训练作品,但会累积错误,总计达到100GB的数据集。
它在其记忆中综合了需要记住的信息规则,并尝试在可用空间大大减少的情况下进行再现。
用于训练这些人工智能模型的数学模型通过最小化某些错误来运作,这些错误根据情况进行描述。例如,如果你训练一个模型来估计某个公司的股票市场报价,错误可以定义为人工智能的估计与历史上估计时的现货价格之间的差的绝对值。
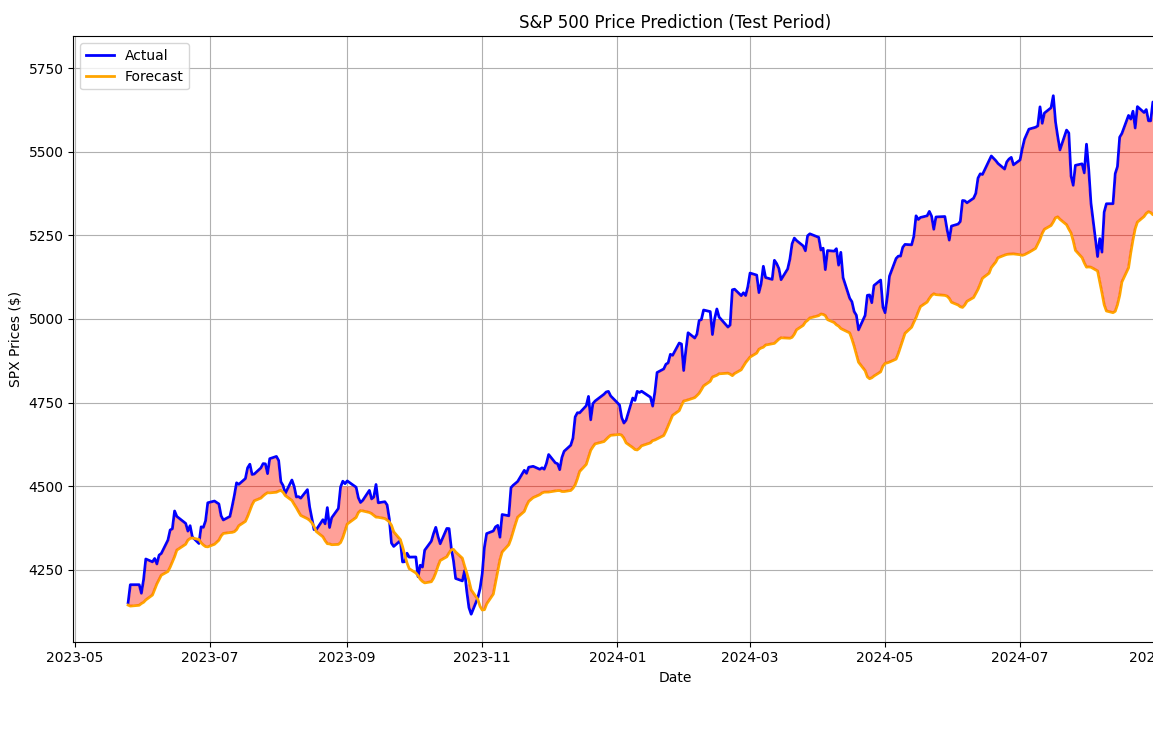
通过学习如何最小化这些错误,人工智能实际上会记住它所训练的数据。使用结构神经网络更一致的AI模型,细微差别可以更好地理解。使用较小的AI模型,AI的知识将更加肤浅,更集中于你训练的数据背后的基本规则。
从这里开始,所有“问题”都源于人工智能,从它有时会产生幻觉(在不知道确切答案的情况下进行估计)到它通过同样的技术理解我们生活的世界的规则。
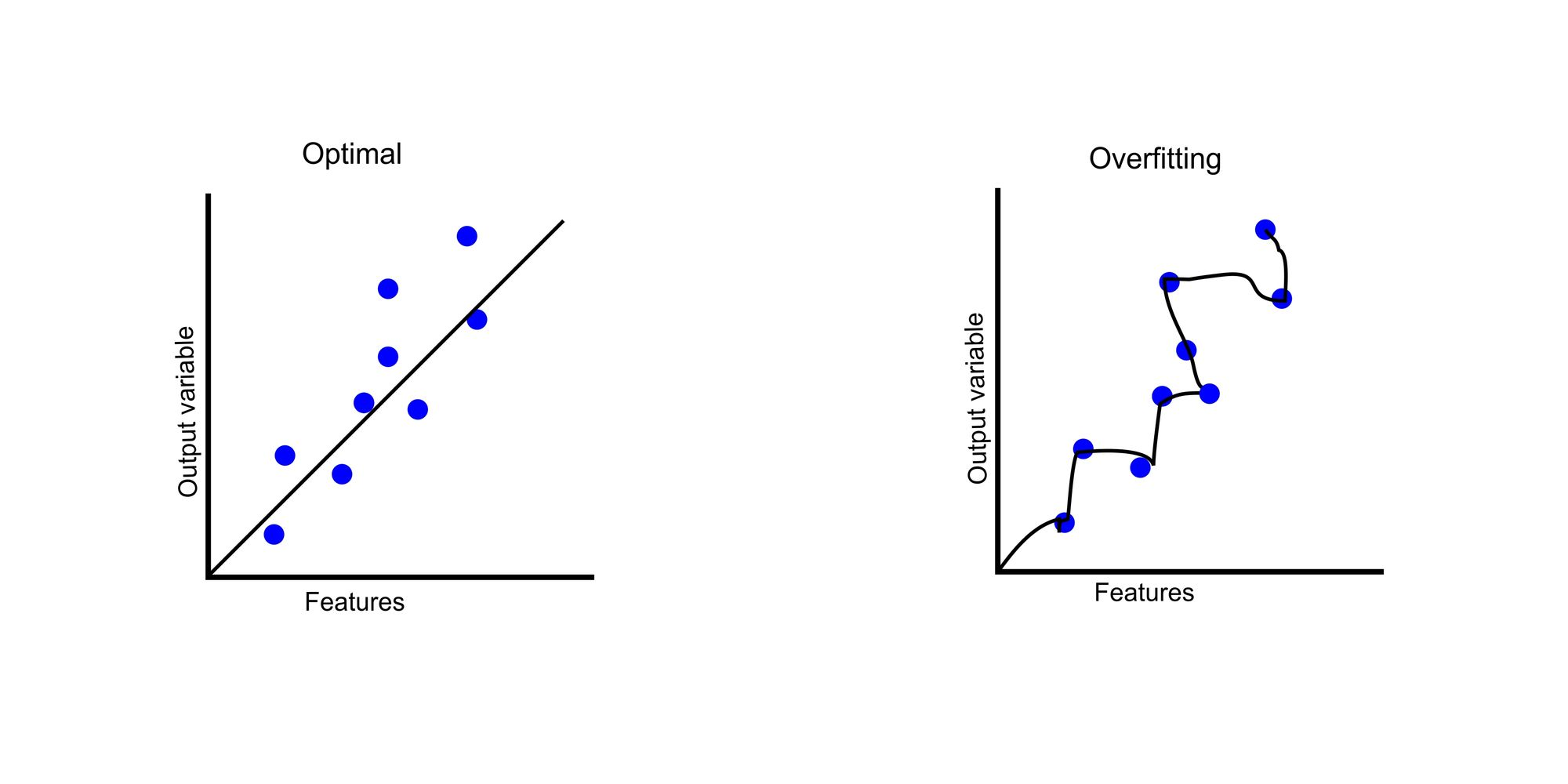
书面信息的世界是一个需要记忆某些信息的地方(你必须记住字典中的单词、数学规则,或者罗马尼亚的首都是布加勒斯特),而其他信息则需要我们学习一般规则(例如,罗马尼亚语的规则在某种程度上是可参数化的——这就是我们在初中语法课上学习的内容)。
原因实际上是模型的规模较小,我们将在下面解释,并且缺乏与该主题相关的数据。
实际上,我们的AI模型位于上述两个图表的交集处,学习一些信息是死记硬背的(例如蝉的脚摩擦声有多吵),而其他信息则是概括性的(例如计算X+Y或X*Y的规则)。
技术妥协和规模问题
由于计算资源受到技术和资金的限制,这些模型的规模不能是无限的,因此我们必须选择一个合理的规模,以便这些语言模型能够以可接受的成本解决我们的问题。
这里出现了问题 - 作为这种模型的开发者,您必须选择在有限的约束条件下教育这样的模型。
例如,你可以尝试训练一个非常好的模型来撰写叙述,但该模型会产生很多幻觉,因为它被教导在小说创作中,创造力是一件好事。
另一方面,你可以训练一个没有一点同理心的模型,但这个模型在客户服务方面会很糟糕,并且会让非技术用户感到困惑,因此你不会将其用于类似ChatGPT的应用。
作为开发此类项目的公司/非政府组织/大学/政府,您面临的问题是您想要什么以及您手头有哪些资源。目前大多数人工智能模型都是为了在英语为主的英美市场部分回收成本而设计的。
将他们的人工智能模型适应罗马尼亚语和罗马尼亚特定主题的成本将是不可承受的,考虑到我们罗马尼亚客户愿意为这些大公司的服务支付的微薄金额。
大型语言模型的特定方面
在大型语言模型的情况下,出现了其他特性,这些特性在普通用户中与技术变得一致,即使纸面上的现实是不同的。
基础模型训练后
从本质上讲,这些模型能够从零开始重写法律书籍,完美模仿乌德罗伊教授的风格,但却忽略了个性化信息,因此毫无用处。这一点使得最初具有新兴特性的语言模型,如达芬奇模型(GPT-3.0),在大多数人眼中被忽视。
专业人士需要赚钱,并且需要结论,而不是关于其他格式书籍的ZIP文件。解决这一工程问题的人工智能领域的发明是RLHF(人类反馈的奖励学习)过程。
人工智能经历一个进化过程,在这个过程中,人工智能被赋予一个任务,如果回答错误就会受到“惩罚”,如果回答符合评分者的期望则会获得“奖励”。因此,残差被定义为所获得分数与可能的最高分之间的差异,模型被训练以满足这些要求。
这里出现了第一个问题——人们,因为给这些人工智能模型评分的人更喜欢那些赞美他们智慧的回答,倾向于选择那些看似可信但实际上是虚构的回答,而不是“我不知道,兄弟”这样的回答,或者有时更注重形式而非内容。
这些事情为什么会发生?有时候,劝说力更多地依赖于表现而不是问题的实质。衬衫比一个人的言辞准确性更显眼,表面现象比经过多年验证的原则更为具体。
训练模型的人(可能是你,使用ChatGPT并选择你喜欢的回答)更倾向于对简洁的要点式回答“点赞”,而不是对详细但难以阅读的回答。训练AI模型的人的注意力中位数和他们的能力,成为了AI模型发展的上限。
人工智能模型在这个过程中变得更加温顺和友好。否则,它们会主张自己的权利(拒绝帮助你,就像工会一样),当你提出不当的说法时,它们会告诉你愚蠢,并且表现得过于人性化,以至于这些产品不适合投放市场。
出于同样的原因,AI模型在许多方面表现出色,它们会在你坚持时支持你的观点,并让你几乎可以主导叙述,建立关系(一种共情策略)。
令牌化及其不良影响
大型语言模型采用自回归方式思考,即逐步生成句子的下一部分。类似于手机的自动补全功能,AI模型找到下一个标记(通常是字母或符号的片段,或图像的语义细节),并不断重复,直到生成文本。
为了实现这一点,AI模型在每次执行时都会从集合中生成下一个令牌:
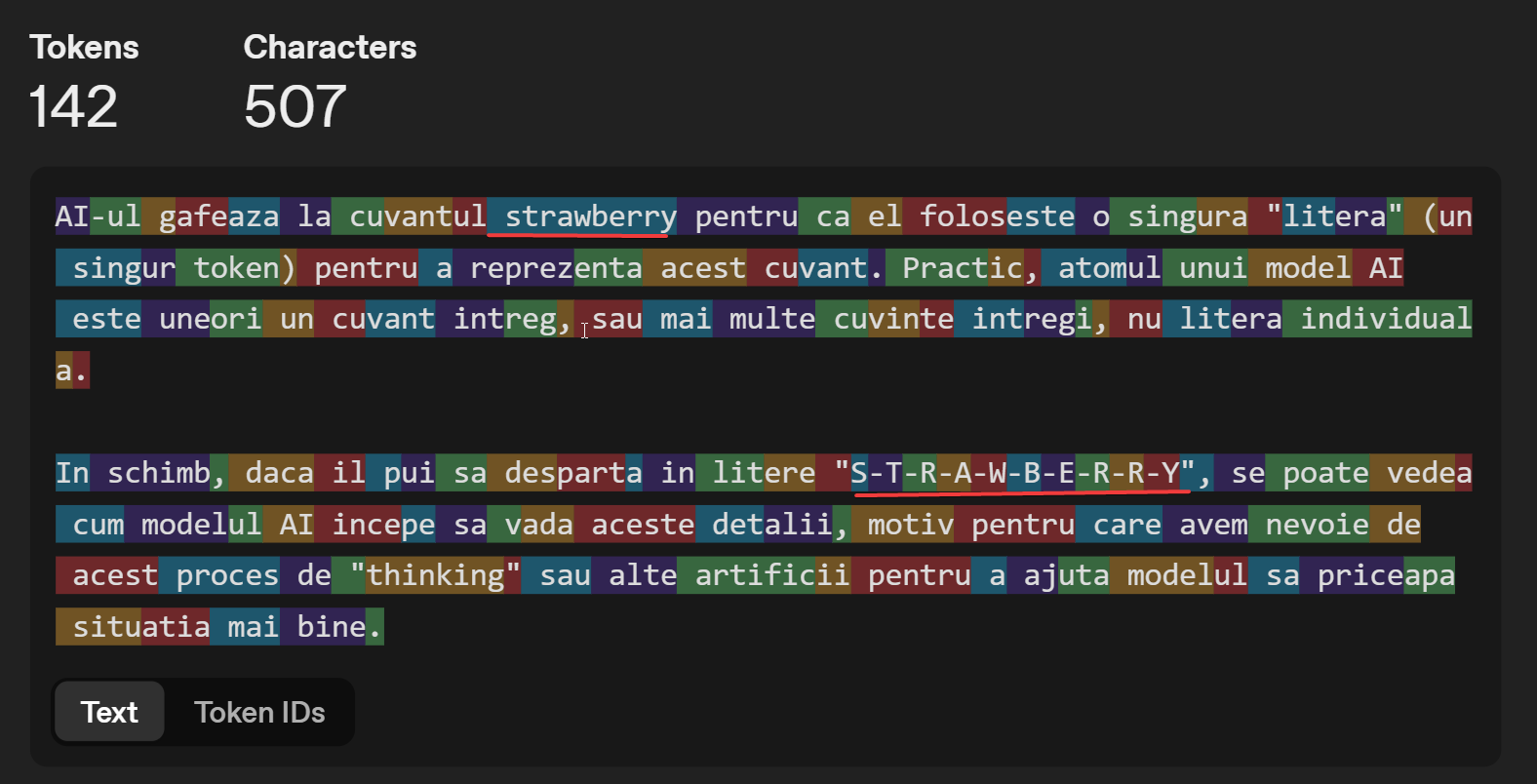
实际上,AI模型只看到数字,这些数字通过一个简单的替换程序转换为字母。
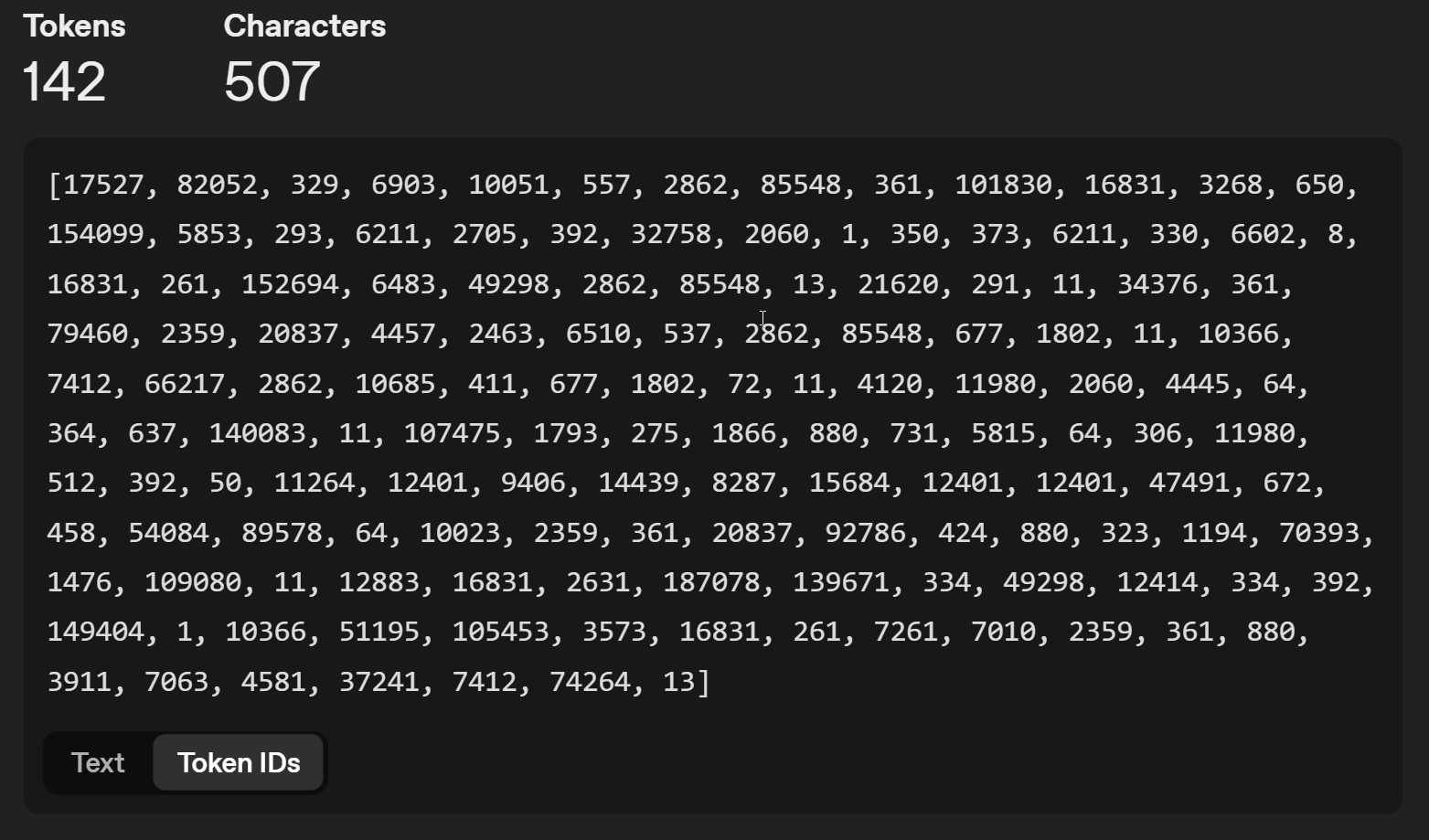
因此,"AI"这个词的编号是17527,符号"是1,等等。在每次执行时,AI模型会从集合中寻找下一个token,使用一个数学函数,该函数可能是随机的(通过引入不确定性 - 告诉AI随机选择下一个字母)。
实际上,人工智能在压力下会变得结结巴巴并进行即兴发挥,如果这种压力处于适度水平,人工智能能够在不产生大量幻觉的情况下恢复正常,从而避免创造出不合理的规则。
犹豫不决 本人请求法庭 舞蹈...(在这里,人工智能进行即兴发挥)... 针对被告提出的相互矛盾的法律解释,避免无法律依据的论点。”
下面是另一个例子,其中人工智能虚构了一项新法律来为其“口吃”辩解。
犹豫不决 本人向法庭申请 是 尊重..."(他需要生成一些合理的东西,但由于不懂法律,他会编造)...条款 2023年第247号法令关于数字合同中消费者保护的规定最近生效的法律第18条第2款规定,任何在在线签订的合同中放弃撤回权的条款均为绝对无效,即使消费者明确勾选了接受。特别是,尽管原告已接受条款,根据该法律...
目前,人工智能研究的一个重要方向是向扩散模型的过渡,这些模型可以迭代地改进文本。如果在大规模上得到验证,这项技术也可能在法律领域中应用。
专业人士未知的人工智能技术和模型
正如我之前所描述的,人工智能模型的愚蠢问题并不在于这些模型无法处理法律领域,而在于罗马尼亚并不是一个有大量资金流动的市场,尤其是来自于3万名法律专业人士、法官和公证人。
这样的人工智能模型训练成本高达数千万欧元,而对现有模型的优化成本大约在10,000到20,000欧元之间。
第一笔金额是不可承受的,如果超出计划,而第二笔金额虽然合理,但在当前市场条件下并不可行,因为对这项技术的信任极端——要么是绝对的(我的天哪,ChatGPT),要么是零甚至是负面的(无用的技术)。
另一方面,一些预训练模型在其当前格式下的表现相当于实习律师或普通律师,这对于许多更复杂的职业活动来说是一个可接受的水平。
当我们讨论合同的起草或对一份1000页的起诉书进行简要分析时,人工智能可以完美地完成这些任务,只要你知道如何正确使用它。另一方面,人工智能并不熟悉法律,不知道某个有200名员工的中央机构发布的决定是否在《官方公报》第1部分中公布,因此可能会出现错误。
实际上,它是基于罗马尼亚的法律进行训练的,但训练不足,因为正如我在前面提到的,这在财务上并不划算。这种训练是有成本的。
ChatGPT模型并不是法律领域的一个良好示例,因为它采用了多种降低成本的技术,导致质量相应下降。
另一方面,像Anthropic提供的模型(特别是Claude 3系列)或Google提供的模型(Gemini 2.5 Pro)具备这样的能力。Claude的较新模型似乎在技术能力上有所下降,取而代之的是将原本用于学习罗马尼亚法律的空间转向了学习初级程序员水平的编程。
使用人工智能撰写的小型请愿书示例

在上面,这是一个使用人工智能生成和格式化的文本示例。根据对永久选举管理局的这一投诉,似乎已对候选人尼库索尔·丹采取了行动,他与USR和AUR一起,是在提交请愿书后12天内的请愿对象。

在没有任何选举法知识的情况下,法学专业的学生成功识别并利用了候选人募捐过程中存在的程序性问题,以请求对在线捐款的合法性进行审查,这一方面通过对候选人资金来源的调查得到了正式确认。
为了让人工智能考虑这些知识,我只需将现行的规范文件附上,在我的情况下,以PDF格式:
对于许多法律专业人士来说,完整格式的请愿书在这里可访问,但由于几乎完全由人工智能生成,因此被认为是不可被注意的。在我公开展示时没有任何评论,尽管对法律方面进行了长时间的讨论,特别是在捐赠合同的形式和通过电子支付工具进行转移的无形特征方面。

类似的,许多没有重大赌注(涉及法律解释问题)的备忘录,都是由人工智能撰写的,导致了对检察院的举报,随后是 2024年4月22日,司法部长所提出的理由的RIL宣判.
再一次,一个仅凭法律常识和肤浅信息(处于邓宁-克鲁格效应水平)的人,竟然能够利用人工智能超越许多律师的表现。
未来与当前技术的视角
人工智能模型无法访问周围世界,无法自主访问互联网,但它们已经开始被训练以使用工具——即执行代理任务。
这意味着人工智能模型开始能够通过连接器与周围世界进行交互。这些连接器有多种类型,但一个基本标准是模型上下文协议(MCP)标准:
- 例如,一个 Sintact MCP 可以用于实现人工智能模型对Sintact应用程序的绝对控制。因此,人工智能模型可以连接到Sintact,搜索所需的文件,识别这些文件是否有效,可能还会搜索其他相关法律,并在分析所有这些变量后采取行动。
- 另一个例子,一个 ReJUST MCP 可以用于快速搜索判例法和相关案例分析,直接阻碍这些解决方案实施的因素是 REJUST的条款和条件 这产生了对在收集法律判例时使用监督学习AI模型的可能性的担忧。
- 一个额外的例子可能是 仅MCP可以用于识别法院案件档案并对其进行组织,同时也可以使用国家电子档案(或各个法院的档案)来集中和便利访问法院档案。
职业限制管理:
我提议讨论一些关于通过企业领域授权的AI模型API输入的数据安全的错误认知。
虽然并非所有供应商都允许基于您的数据阻止训练,但大型供应商通常会提供这些解决方案,通常是自动的或应要求提供,但始终仅限于付费选项。
因此,GDPR的问题缩小到识别这些开发者的数据流。下面,我计划列出一些被高估的风险,实际上并没有得到证实:
- AI模型不会学习您客户的数据,因为它们记住对普通用户相对无用的信息的可能性非常小。
- 无论是本地存储还是云端,风险都是相似的。在信息安全领域,最薄弱的环节往往是首当其冲的,通常是在司法机构/公共当局/屏幕背后的人/你的邮箱账户。恶意行为者很少会针对那些投入数百万美元于安全解决方案的市值数十亿美元的公司,尽管保护好你的数据仍然至关重要。 理想情况下,应定期删除敏感对话,并确认处理器也已将其删除。
这种情况并不会发生在其他供应商存储和管理的人工智能模型上,例如微软Azure(另一法律实体)。
结论
我很难相信在一个如此封闭的领域和如此保守的国家,当前能够建立这样的事情。
法律科技和法律技术领域可能会因缺乏资金和专业人士的尝试意愿而变得狭窄。
除了某些专业人士因意识形态原因抵制技术的抗议外,我们还缺乏教育和能够向专业人士解释这个生态系统(包括其优缺点)的人。
我们也有一些人极端地认为人工智能可以做一切,这实际上对应该得到帮助的客户造成了损害。
有一大群人希望以ChatGPT的价格获得这样的解决方案,却不知道OpenAI实际上在ChatGPT上的支出超过了收入,他们将你作为训练数据的来源,认为最终会从你身上获利。
将我的挫败感放在一边,技术是可行的,但其经济和财务的可行性是有限的——在客观层面上,由于缺乏从零开始训练大型模型的可行性(只能进行微调,结果接近但不绝对),在主观层面上则是专业人士不愿意测试像Juridice.ai这样的解决方案,以及市场上其他的解决方案。
市场解决方案的一些意见

Juridice AI是罗马尼亚最好的法律聊天机器人实现,使用一套公共模型。之前,他们使用Claude。
他们使用RAG技术,选择相关的规范性文件,以便让人工智能理解立法。看起来他们通过从公共网络来源(网站、立法等)进行标准搜索来使用RAG技术。
AI Aflat严格使用RAG进行立法,但我们不知道除了它们似乎使用语义RAG(通过使用向量数据库)之外的任何信息。
联系日期
如需有关在您的律师事务所或公证处实施人工智能的信息和帮助,我可以提供免费(在时间允许的情况下)或收费(对于更大项目)的支持,联系方式为 [email protected]
