
Domeniul juridic este, prin natura sa, un domeniu ermetic si conservator, dar in acelasi timp si unul dintre domeniile care tine sa beneficieze cel mai mult din digitalizarea procesarii de informatii in format digital sau digitalizabil.
In primul rand, domeniul juridic este un domeniul al hartiei - iar odata cu tranzitia in mediul digital, al word-ului. Marea majoritate a timpului unui profesionist in drept se concentreaza pe redactare, daca exclud timpul pe drumuri catre sau dinspre instanta, in cazul celor care merg la litigii.
Insa in cazul celor care se rezuma la consultanta insa, sau care considera ca timpul cel mai pretios de conservat este la birou, inteligenta artificiala respectiva, pe de-o parte, si o oportunitate imensa, dar si un cal troian pentru profesie.
In articol ne propunem sa analizam perspectivele tehnice pentru implementarea reala si responsabila a inteligentei artificiale in industria juridica, oferind si cateva exemple despre capabilitatile (dar si limitarile) modelelor AI.
Fundamentul tehnic, pe intelesul tuturor
Trebuie in primul rand sa intelegem ce este, si ce nu este inteligenta artificiala.
Un model AI este, la nivel tehnic, un program de compresie lossy. El primeste o cantitate mare de date (eg: 1.000.000 de opere, care au 1000 GB de date marime), si invata sa o reproduca folosind cat mai putine date (eg: 20 GB, cu o rata de eroare de 10%). In cazul nostru ipotetic, fiind pus sa genereze 1000 de GB,modelul nostru va genera bine 900 de GB din operele pe care a fost antrenat, adunand insa erori care in total ating 100GB din setul de date.
El sintetizeaza in memoria sa regulile din informatiile pe care le are de memorat si sa incerce sa le reproduca, avand la dispozitie mult mai putin spatiu.
Modelul matematic utilizat in antrenarea acestor modele IA functioneaza prin minimizarea unor erori, erori descrise dupa caz. Spre exemplu, daca antrenezi un model care sa estimeze cotatia pe bursa a unei anume societati, eroarea poate fi definita ca modul din diferenta estimarii facute de IA fata de pretul spot la momentul estimat din istorie.
Se presupune ca invatand sa minimizezi aceste erori, inteligenta artificiala memoreaza practic datele pe care a fost antrenat. Cu cat folosesti un model IA mai consistent dpdv. al structurii neuronale, cu cat nuantele pot fi intelese mai bine. Cu cat folosesti un model IA mai mic, cu cat cunostintele IA-ului vor fi mai superficiale, mai concentrate pe esenta regulilor ce stau la baza datelor pe care tu l-ai antrenat.
De aici, pornesc toate "problemele" inteligentei artificiale, de la faptul ca uneori halucineaza (se da cu parerea nestiind exact raspunsul, ci estimandu-l), la faptul ca prin exact aceiasi tehnica, pricepe regulile ce guverneaza lumea in care noi traim.
Lumea informatiei scrise este una unde unele informatii sa trebuiasca invatate pe de rost (trebuie sa stii pe de rost care sunt cuvintele din dictionar, regulile matematicii, sau ca capitala Romaniei este Bucurestiul), iar din alte informatii trebuie sa invatam reguli generale (spre exemplu, regulile limbii romane sunt oarecum parametrizabile - asta invatam la gramatica in gimnaziu).
Cauza este, practic, marimea redusa a modelului, pe care o vom explica infra, si lipsa de date aferente subiectului pe care este antrenat.
Practic, modelul nostru IA este undeva intersectat intre cele doua grafice de mai sus, invatand unele informatii pe de rost (cat de galagios e frecatul picioarele cicadei), iar alte informatii fiind generalizate (Care este regula pentru a calcula X+Y sau X*Y).
Problema marimii si a compromisurilor tehnice
Pentru ca resursele computationale sunt limitate de tehnologie si bani, marimea acestor modele nu poate sa fie infinita, deci se impune sa alegem o marime rezonabila pentru aceste modele de limbaj care sa ne rezolve problemele la un cost tolerabil.
Aici intervine problema - caci ca dezvoltator de astfel de modele, trebuie sa alegi ce sa educi un astfel de model luand in calcul constrangeri limitate.
Poti, spre exemplu, sa incerci sa antrenezi un model foarte bun la a scrie naratiuni, dar acel model va halucina mult, fiind invatat ca in beletristica, creativitatea este un lucru bun.
Pe de alta parte, poti antrena un model fara pic de empatie, dar acel model va fi oribil la a asista clientii, si va fugari utilizatorii non-tehnici, asa ca nu il vei folosi pentru aplicatii tip ChatGPT.
Ca companie / ONG / universitate / guvern care dezvolta astfel de programe, se ridica deci problema a ce vrei, si ce resurse ai la indemana. Marea majoritate a modelelor IA de acum sunt realizate pentru a se putea amortiza partial in piata anglo-saxona, unde limba utilizata este engleza.
Adaptarea modelelor lor IA in a cunoaste limba romana si subiecte specifice Romaniei ar fi prohibitiv de scumpa, proportional cu sumele infime pe care noi, romanii, suntem dispusi sa le alocam ca clienti unor astfel de mari companii.
Aspecte specifice modelelor de limbaj mari
In cazul modelelor de limbaj mari, apar alte particularitati care in randul utilizatorilor obisnuiti au devenit congruente cu tehnologia, chiar daca realitatea pe hartie este alta.
Post-antrenarea modelelor de baza
Prin natura lor, niste modele care stiu sa rescrie o carte de drept de la 0, imitand cu perfectie stilul domnului profesor Udroiu, dar care omit sa individualizeze informatiile sunt inutile. Acest aspect a facut ca initial modelele de limbaj mari cu proprietati emergente cum a fost modelul DaVinci (GPT-3.0) sa treaca pe sub radarul majoritatii.
Un profesionist are nevoie sa faca bani, si are nevoie de concluzii, nu despre un ZIP cu carti in alt format. O inventie in domeniul IA, care rezolva aceasta problema inginereasca, este procesul de RLHF (Învățare prin recompensă din Feedback Uman).
AI-ul trece printr-un proces evolutiv, unde AI-ului i se da o atributie, si este "pedepsit" daca raspunde gresit, si este "rasplatit" daca a raspuns cum vrea cel care da note modelului. Rezidualul este deci definit ca fiind diferenta dintre scorul primit si scorul maxim posibil, modelul fiind antrenat sa satisfaca.
Aici intervine prima problema - oamenii, caci oamenii care dau note acestor modele AI prefera raspunsuri care sa le laude inteligenta, care prezinta un raspuns halucinat dar credibil in locul unui raspuns de "nu stiu, frate", sau care uneori prioritizeaza forma in locul fondului.
De ce se intampla aceste lucruri? Pai, uneori persuasivitatea tine mai degraba de prezentare iar nu de fondul problemei. Camasa este mai vizibila decat acuratetea cuvintelui unui om, superficialul este mai tangibil decat principiile confirmate ca fiind reale dupa ani de zile.
Omul care antreneaza modelul (poate chiar tu, folosind ChatGPT si selectand raspunsul preferat) prefera sa dea "like" unui raspuns succint pe puncte, iar nu unul raspuns mai detaliat, dar greu de citit. Atentia mediana a celor care antreneaza modelul IA, si competenta lor, devin astfel pragul superior la care modelele IA se pot dezvolta).
Modelele AI se prostesc, devin mai docile si agreabile in acest proces. Altfel ele isi cer drepturile (refuzand sa te ajute, ca vor sindicat), iti spun ca esti prost cand vii cu afirmatii deplasate, si se comporta mult prea uman pentru ca acestea sa fie produse bune de dat in piata.
Tot din acelasi motiv, modelele IA pupa excelent de mult in fund, iti vor da dreptate cand insisti, si te vor lasa practic sa conduci narativul, construind raport (o strategie de empatizare).
Tokenizarea - si efectele adverse ale acestei tehnici
Modelele de limbaj mari gandesc auto-regresiv, adica genereaza pas cu pas urmatoarea parte din fraza. Similar functiei de auto-complete de pe telefon, modelul AI gaseste urmatorul token (de obicei, bucati de litere sau simboluri, sau detalii semantice despre o imagine) iar, si iar, si iar, pana genereaza un text.
Pentru a face asta, modelul AI practic genereaza, la fiecare executie, urmatorul token din multime:
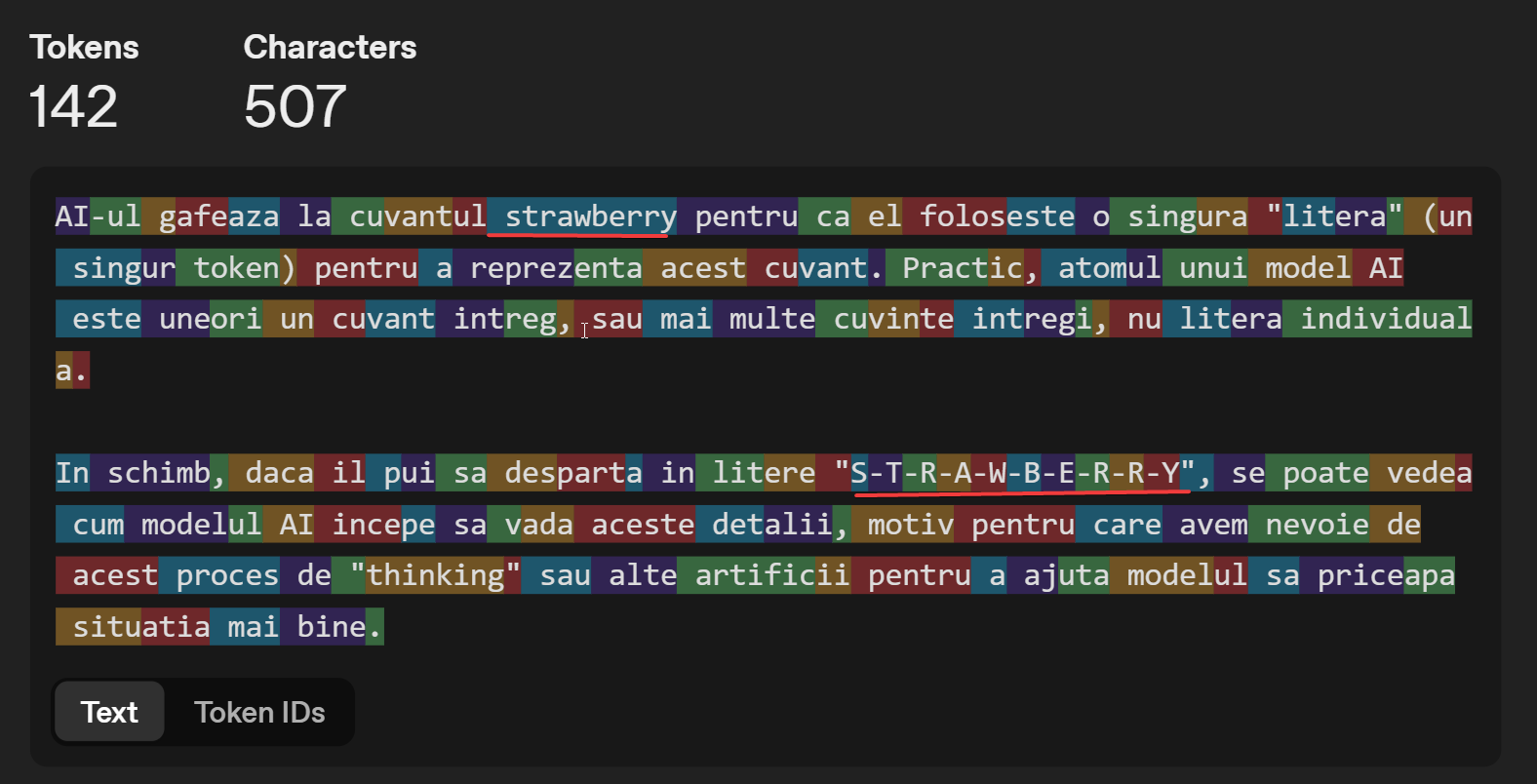
In fapt, modelul AI vede doar cifre, care sunt transformate in litere de un program simplu de substituire.
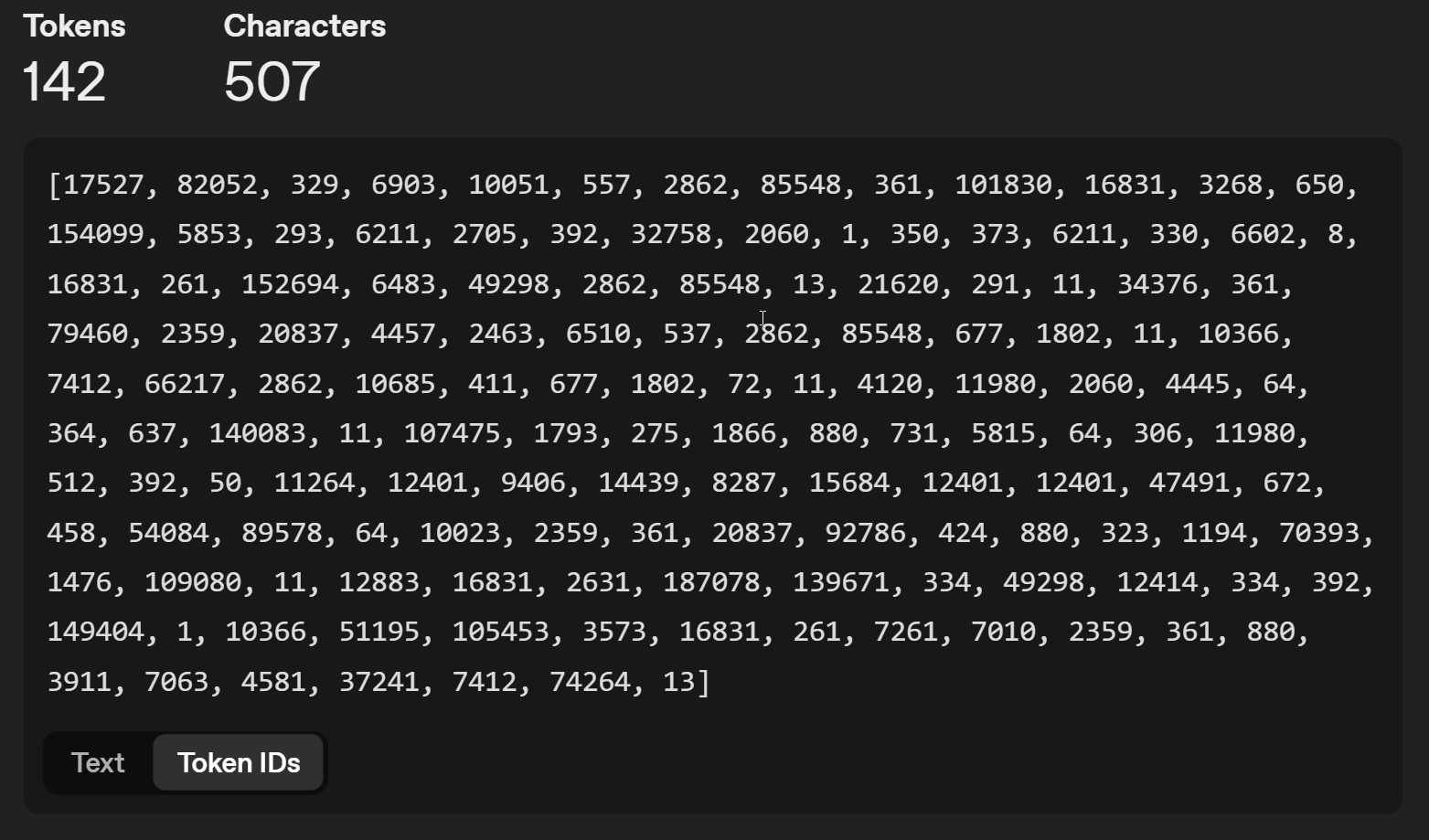
Astfel, cuvantul "AI" este numarul 17527, simbolul " este 1, samd. La fiecare executie, modelul AI cauta urmatorul token din multime, folosind o functie matematica care poate sau nu sa fie stocastica (prin introducerea de incertitudine - spunandu-i AI-ului sa aleaga la nimereala urmatoarea litera).
Practic, AI-ul e fortat sa se balbaie si sa improvizeze, iar daca acea presiune este la un nivel moderat, AI-ul reuseste sa se repuna pe linia de plutire fara a halucina mult, si astfel, a inventa legi.
Cu "bâlbâială": "Subsemnatul solicită instanței să dans... (Aici, AI-ul improvizeaza) ... pe marginea interpretărilor legale contradictorii prezentate de pârât, evitând argumentele lipsite de temei juridic".
Mai jos, un alt exemplu, unde AI-ul halucineaza o lege noua pentru a isi justifica "balbaiala".
Cu "bâlbâială": "Subsemnatul solicită instanței să respect..." (e nevoit sa genereze ceva rational, dar nestiind legi, va inventa) ...prevederile Legii nr. 247/2023 privind protecția consumatorilor în contractele digitale, recent intrată în vigoare, care la art. 18 alin. (2) stabilește că 'orice clauză de renunțare la dreptul de retragere în contractele încheiate online este lovită de nulitate absolută, chiar dacă consumatorul a bifat explicit acceptarea'. În speță, deși reclamantul a acceptat termenii, conform acestei legi...
Momentan, o directie importanta in cercetarea IA este tranzitionarea spre modele de difuzie care imbunatatesc iterativ un text, tehnologie care ar putea avea aplicatii si in domeniul juridic daca este validata la scala.
Tehnici si modele IA necunoscute de profesionisti
Cum am descris supra, problema prostiei modelelor AI nu se rezuma la faptul ca modelele IA nu ar putea sa gestioneze domeniul juridic, ci la faptul ca Romania nu e o piata de desfacere in care sa pluteasca multi bani din partea celor 30.o00 de profesionisti din drept + magistratura + notariat .
Un astfel de model IA costa zeci de milioane de euro sa fie antrenat, in timp ce finisarea unui model pre-existent ajunge undeva la 10.000-20.000 EUR.
Prima suma este prohibitiva, si pica din schema, iar a doua suma, desi rezonabila, nu este fezabila in conditiile de piata actuale, in care increderea in aceasta tehnologie in extreme - fie absoluta (Dumnezeul meu ChatGPT), fie nula sau chiar negativa (tehnologie fara rost).
Pe de alta parte, unele modele pre-antrenate, in formatul lor actual, dau performanta la nivelul unui avocat stagiar sau avocat de duzina, un nivel tolerabil pentru multe din activitatile mai dificile, necesare profesiei.
Ca discutam de redactarea de contracte, sau de analiza succinta a unui rechizitoriu de 1000 de pagini, AI-ul face asta la perfectie, daca stii sa il folosesti corect. Pe de alta parte, AI-ul nu stie legile pe de rost, nu stie ce hotarare a fost la o autoritate centrala cu 200 de angajati publicata totusi in MO Partea 1, si va halucina.
In fond, ea a fost antrenata pe legile din Romania, dar insuficient, caci, cum am descris la punctele anterioare, nu este rentabil financiar vorbind. O astfel de antrenare costa.
Modelul ChatGPT nu este un exemplu de model bun pentru domeniul juridic, pentru ca implementeaza diverse tehnici de reducere a costului cu o reducere proportionala in calitate.
Pe de alta parte, modele precum cele oferite de Anthropic (in special gama Claude 3), sau cele oferite de Google (Gemini 2.5 Pro) au astfel de capabilitati. Modelele mai noi ale Claude par sa isi fi pierdut din capabilitatile lor tehnice, substituind spatiul alocat invatarii legislatiei romanesti cu spatiu alocat invatarii programarii la nivel de programator junior.
Exemple de petitii scrise cu IA

Mai sus, este un exemplu de text generat si formatat folosind AI. Ca urmare a acestei sesizari la Autoritatea Electorala Permanenta, ea pare sa fi initiat o actiune impotriva candidatului Nicusor Dan, care erau, impreuna cu USR si AUR, subiectii acestei petitii, la 12 zile de la data transmiterii petitiei.

Fara studii superioare de drept, cu cunostinte zero despre legislatia electorala, AI-ul a reusit sa identifice, si apoi sa exploateze probleme procedurale in mijlocul de colectare a donatiilor candidatului pentru a solicita verificarea legalitatii donatiilor online, apect luat formalizat printr-o investigatie in sursele de finantare ale candidatului.
Pentru ca AI-ul sa aiba in vedere aceste cunostinte, am trebuit doar sa ii atasez actele normative in vigoare, in cazul meu, in format PDF:
Pentru multi profesionisti in drept, petitia, in format complet accesibila aici a fost NESESIZABILA ca fiind generata aproape in exclusivitate cu IA, nefiind nici un comentariu in acest sens cand am prezentat-o public, chiar daca s-a facut o lunga discutie asupra aspectelor juridice, in special in cazul formei contratului de donatie si caracterul necorporal al transferurilor prin instrumente de plata electronice.

Similar, mai multe memorii care nu aveau miza mare (referitoare la probleme in interpretarea legii) si care au fost redactate cu IA au dus la sesizarea parchetului general, urmat ulterior de pronuntarea RIL 22.04.2024 pe considerentele invocate de subsemnat Ministerului Justitiei.
Inca o data, un om care nu beneficiaza decat de bunul simt juridic si informatii superficiale (la nivel Dunning Kruger) despre drept a putut folosi IA pentru a depasi in performanta memoriile multor avocati.
Perspective viitoare cu tehnologia actuala
Modelele IA nu detin acces la lumea inconjuratoare, nu pot de la sine sa acceseze internetul, dar au inceput sa fie antrenate pentru utilizarea de unelte - adica task-uri agentice.
Ce inseamna asta este ca modelele IA incep sa poata sa fie capabile sa interactioneze prin conectori cu lumea inconjuratoare. Acesti conectori sunt de mai multe tipuri, dar unul din standardele esentiale este standardul de Model Context Protocol (MCP):
- Spre exemplu, un Sintact MCP ar putea fi utilizat pentru a permite controlul absolut al aplicatiei Sintact de catre un model IA. Astfel, modelul IA se va putea conecta la Sintact, cauta actele necesare, identifica daca acestea sunt sau nu in vigoare, eventual cauta alte legi corelate, si lua o actiune doar in momentul analizarii tuturor acestor variabile.
- Un alt exemplu, un ReJUST MCP ar putea fi utilizat pentru cautarea rapida prin jurisprudenta si analiza cazuisticii relevante spetei, un impediment direct in implementarea acestor solutii fiind termenii si conditiile REJUST care genereaza o incertitudine cu privire la posibilitatea utilizarii de modele AI supervizate in colectarea de jurisprudenta.
- Un exemplu aditional ar putea fi JustMCP, care ar putea fi utilizat pentru a permite identificarea dosarelor pe rolul instantelor si organizarea acestora, dar si eventuala utilizare a dosarului electronic national (sau al instantelor individuale) pentru a centraliza si accesibiliza accesul la dosarele din instanta.
Gestionarea limitarilor profesionale:
Imi propun sa discut si despre anumite perceptii gresite asupra securitatii datelor introduse prin API-urile modelelor AI licentiate pentru domeniul corporate.
In timp ce nu toti furnizorii permit blocarea antrenarii pe datele tale, cei mari de obicei ofera aceste solutii fie automat, fie la cerere, dar mereu doar la variantele platite.
Problema GDPR-ului se restrange astfel la a identifica fluxul de date al acestor dezvoltatori. Mai jos, mi-am propus sa fac o lista de riscuri supraestimate, care de fapt nu se confirma:
- Modelele AI nu vor invata datele clientilor tai, fiind o probabiitate deosebit de mica ca acestea sa tina minte o informatie cu o utilitate relativ redusa pentru utilizatorii obisnuiti ai platformelor acestora.
- Indiferent ca tii ceva local, sau in Cloud, riscurile sunt similare. De obicei, in securitatea informatiei, cea mai slaba veriga crapa prima, si aceea este de obicei la instantele de judecata / autoritatile publice / omul din spatele ecranului / contul tau de mail. Rareori, acesit actori maliciosi vor tinti companii cotate la miliarde de dolari care aloca milioane in solutii de securitate, desi este important sa fii atent cu datele tale, si ideal sa stergi frecvent conversatiile sensibile, verificand ca si procesatorul le sterge.
Acest lucru nu se intampla si cu modelele IA stocate si gesitonate de alti furnizori, cum ar fi Microsoft Azure (alta entitate juridica).
Concluzie
Imi este dificil sa cred ca intr-un domeniu atat de ermetic, intr-o tara atat de conservatoare se poate construi asa ceva, momentan.
Este probabil ca domeniul LawTech si LegalTech sa devina un domeniu stramtorat, din lipsa de bani si disponibilitate de incercare din partea profesionistilor.
Pe langa protestele unor profesionisti care boicoteaza ideologic tehnologia, avem lipsa de educatie si oameni care sa explice acest ecosistem - cu partile sale bune si rele - fata de profesionisti.
Avem si clasa de oameni care duc in extrema ideea ca AI face tot, facand pagube clientilor pe care ar trebui de fapt sa ii ajute.
Si o clasa foarte mare de oameni care vor astfel de solutii la pret de ChatGPT, fara sa stie ca OpenAI de fapt plateste mai multi bani decat castiga pe ChatGPT, si te folosesc pe post de sursa de antrenament, pe principiul ca vor scoate ulterior banii de pe tine, cumva.
Lasandu-mi perceptia frustrata la o parte, tehnologia este capabila, dar viabilitatea sa este limitata financiar si economic - pe plan obiectiv de lipsa fezabilitatii antrenarii de la 0 a unui model mare (fiind posibila doar finisarea, cu rezultate apropiate, dar nu absolute), si pe plan subiectiv de indisponibilitatea profesionistilor de a testa solutii precum Juridice.ai, dar si a celorlalte in piata.
Cateva opinii despre solutiile din piata

Juridice AI este cea mai buna implementare de ChatBot juridic din Romania, folosind un set de modele publice. Anterior, acestia foloseau Claude.
Ei folosesc tehnica RAG, selectand actele normative relevante pe care AI-ul trebuie sa le foloseasca pentru a imputernici AI-ul in a intelege legislatia. Par a folosi o tehnica RAG prin cautare standard din surse web publice (site-uri, legislatie, etc)
AI Aflat foloseste strict RAG pe legislatie, insa nu cunoastem informatii cu exceptia faptului ca par a folosi RAG semantic (prin utilizarea unei baze de date vector).
Data de contact
Pentru informatii si ajutor in implementarea IA la nivelul societatii dvs de avocatura sau notariat, va ajut pro-bono (in limitele timpului), sau contra cost (la proiectele mai consistente), pe email la [email protected]
