
Le domaine juridique est, par nature, un domaine hermétique et conservateur, mais en même temps, c'est l'un des domaines qui bénéficie le plus de la numérisation du traitement des informations au format numérique ou numérisable.
Tout d'abord, le domaine juridique est un domaine de papier - et avec la transition vers le numérique, de Word. La grande majorité du temps d'un professionnel du droit est consacrée à la rédaction, en excluant le temps passé en déplacement vers ou depuis le tribunal, pour ceux qui se rendent aux litiges.
Dans le cas de ceux qui se limitent à la consultation, ou qui estiment que le temps le plus précieux à préserver est au bureau, l'intelligence artificielle en question représente, d'une part, une immense opportunité, mais aussi un cheval de Troie pour la profession.
Dans cet article, nous proposons d'analyser les perspectives techniques pour une mise en œuvre réelle et responsable de l'intelligence artificielle dans l'industrie juridique, en fournissant également quelques exemples des capacités (mais aussi des limites) des modèles d'IA.
Les bases techniques, expliquées de manière accessible à tous
Nous devons d'abord comprendre ce qu'est, et ce que n'est pas, l'intelligence artificielle.
Un modèle d'IA est, sur le plan technique, un programme de compression lossy. Il reçoit une grande quantité de données (par exemple : 1.000.000 d'œuvres, totalisant 1000 Go de données), et apprend à les reproduire en utilisant le moins de données possible (par exemple : 20 Go, avec un taux d'erreur de 10 %). Dans notre cas hypothétique, étant chargé de générer 1000 Go, notre modèle générera correctement 900 Go des œuvres sur lesquelles il a été entraîné, accumulant cependant des erreurs qui atteignent au total 100 Go du jeu de données.
Il synthétise dans sa mémoire les règles à partir des informations qu'il doit mémoriser et essaie de les reproduire, disposant de beaucoup moins d'espace.
Le modèle mathématique utilisé pour entraîner ces modèles d'IA fonctionne en minimisant certaines erreurs, erreurs décrites selon le cas. Par exemple, si vous entraînez un modèle pour estimer la cotation boursière d'une entreprise particulière, l'erreur peut être définie comme la valeur absolue de la différence entre l'estimation faite par l'IA et le prix au comptant au moment de l'estimation dans l'historique.
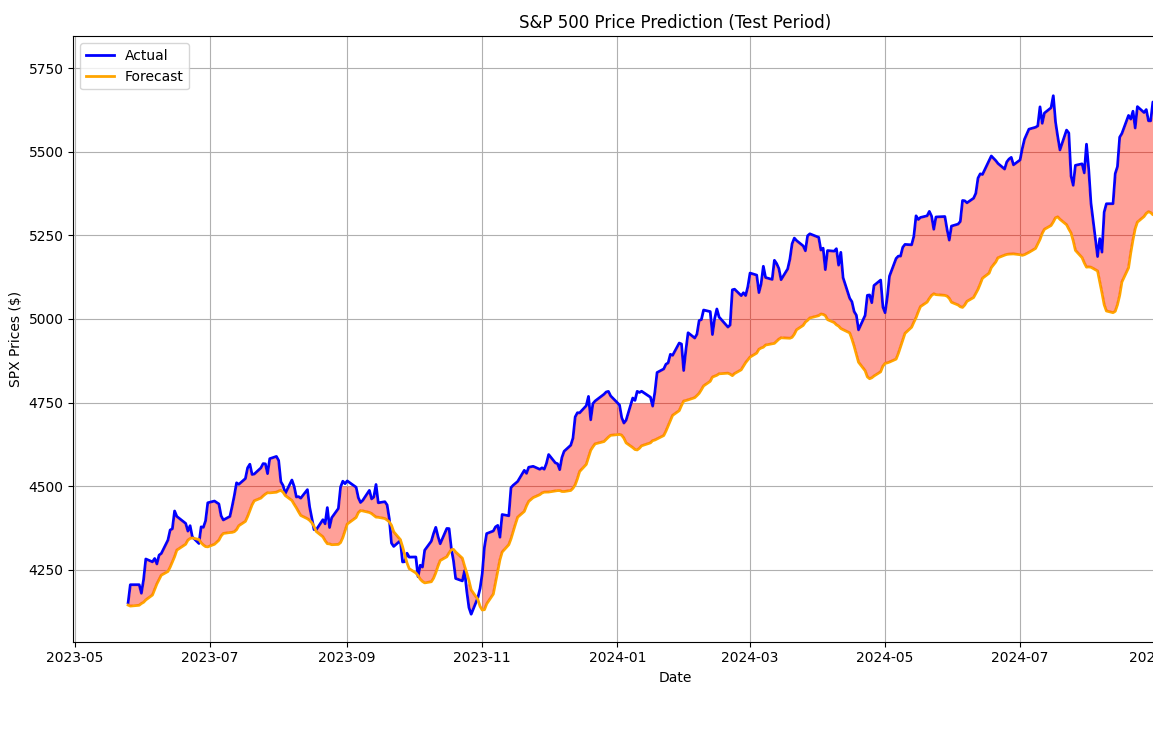
On suppose qu'en apprenant à minimiser ces erreurs, l'intelligence artificielle mémorise en pratique les données sur lesquelles elle a été entraînée. Plus vous utilisez un modèle d'IA cohérent en termes de structure neuronale, mieux les nuances peuvent être comprises. Plus vous utilisez un modèle d'IA de petite taille, plus les connaissances de l'IA seront superficielles, se concentrant davantage sur l'essence des règles qui sous-tendent les données sur lesquelles vous l'avez entraînée.
De là, naissent tous les "problèmes" de l'intelligence artificielle, allant du fait qu'elle hallucine parfois (elle donne son avis sans connaître exactement la réponse, mais en l'estimant), à celui qu'avec exactement la même technique, elle comprend les règles qui régissent le monde dans lequel nous vivons.
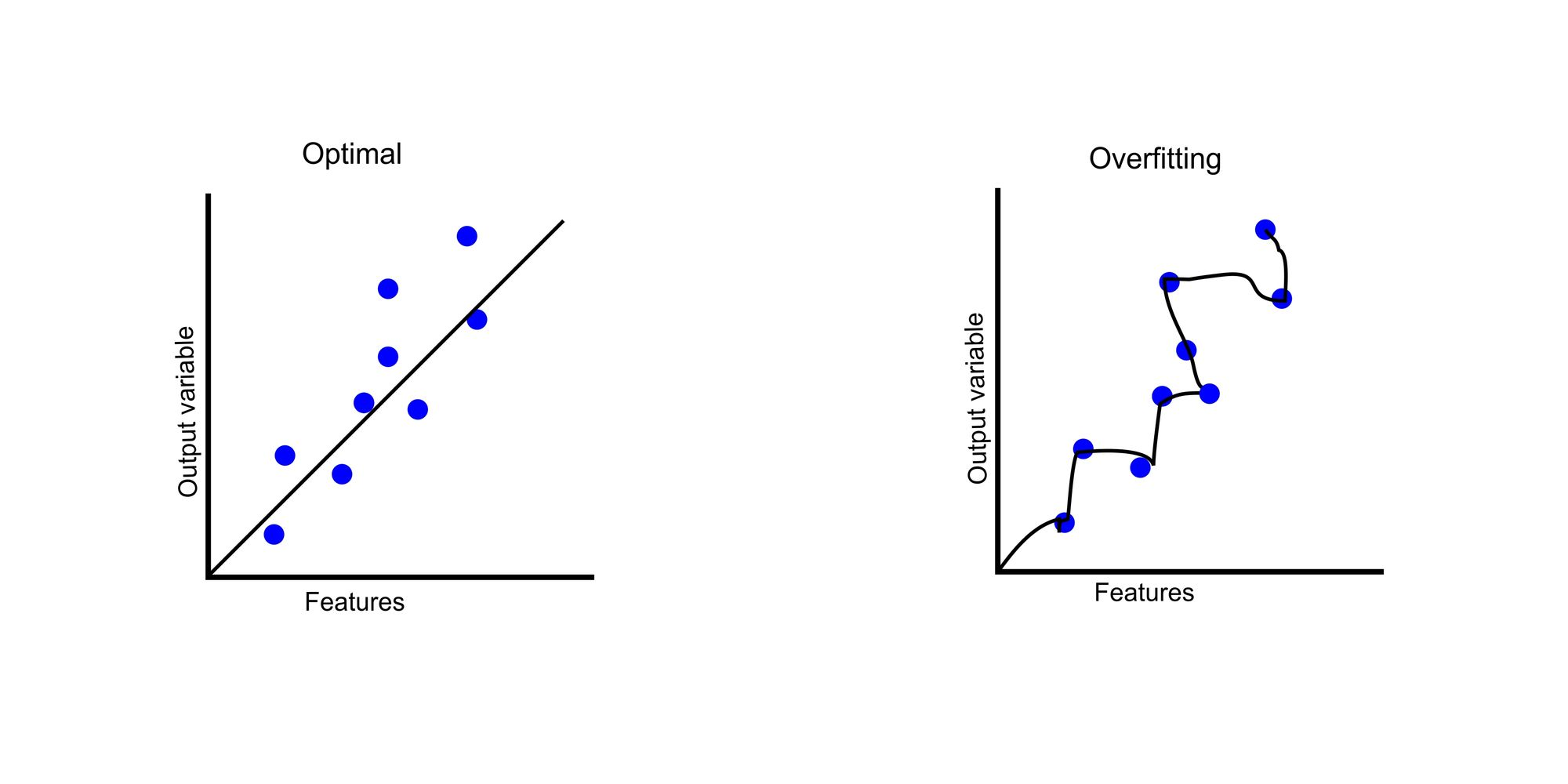
Le monde de l'information écrite est un domaine où certaines informations doivent être apprises par cœur (il faut savoir par cœur quels sont les mots du dictionnaire, les règles de mathématiques, ou que la capitale de la Roumanie est Bucarest), tandis que d'autres informations nécessitent l'apprentissage de règles générales (par exemple, les règles de la langue roumaine sont en quelque sorte paramétrables - c'est ce que nous apprenons en grammaire au collège).
La raison est, en pratique, la taille réduite du modèle, que nous expliquerons ci-dessous, et le manque de données relatives au sujet sur lequel il a été entraîné.
En pratique, notre modèle IA se situe quelque part à l'intersection des deux graphiques ci-dessus, apprenant certaines informations par cœur (à quel point le frottement des pattes de la cigale est bruyant), tandis que d'autres informations sont généralisées (quelle est la règle pour calculer X+Y ou X*Y).
Problème de taille et de compromis techniques
Étant donné que les ressources informatiques sont limitées par la technologie et le budget, la taille de ces modèles ne peut être infinie, il est donc nécessaire de choisir une taille raisonnable pour ces modèles de langage qui résoudra nos problèmes à un coût acceptable.
Ici se pose le problème - en tant que développeur de tels modèles, il faut choisir ce que l'on va éduquer dans un tel modèle en tenant compte de contraintes limitées.
Par exemple, tu peux essayer d'entraîner un modèle très performant pour écrire des récits, mais ce modèle aura beaucoup d'hallucinations, car il a été appris que dans la fiction, la créativité est une bonne chose.
D'un autre côté, vous pouvez entraîner un modèle sans aucune empathie, mais ce modèle sera horrible pour assister les clients et fera fuir les utilisateurs non techniques, donc vous ne l'utiliserez pas pour des applications de type ChatGPT.
En tant qu'entreprise / ONG / université / gouvernement développant de tels programmes, la question se pose donc de ce que vous souhaitez et des ressources dont vous disposez. La grande majorité des modèles d'IA actuels sont conçus pour pouvoir être partiellement amortis sur le marché anglo-saxon, où la langue utilisée est l'anglais.
L'adaptation de leurs modèles d'IA pour comprendre la langue roumaine et des sujets spécifiques à la Roumanie serait prohibitive en termes de coûts, proportionnellement aux sommes dérisoires que nous, Roumains, sommes prêts à allouer en tant que clients à de telles grandes entreprises.
Aspects spécifiques des grands modèles de langage
Dans le cas des grands modèles de langage, d'autres particularités apparaissent qui, parmi les utilisateurs ordinaires, sont devenues congruentes avec la technologie, même si la réalité sur le papier est différente.
Après l'entraînement des modèles de base
Par leur nature, des modèles capables de réécrire un livre de droit depuis le début, imitant à la perfection le style de Monsieur le Professeur Udroiu, mais omettant de personnaliser les informations, sont inutiles. Cet aspect a conduit à ce que, initialement, les grands modèles de langage avec des propriétés émergentes, comme le modèle DaVinci (GPT-3.0), passent inaperçus pour la majorité.
Un professionnel a besoin de gagner de l'argent et a besoin de conclusions, pas d'un fichier ZIP avec des livres dans un autre format. Une invention dans le domaine de l'IA qui résout ce problème d'ingénierie est le processus de RLHF (Apprentissage par Renforcement à partir de Feedback Humain).
L'IA traverse un processus évolutif, où elle se voit attribuer une tâche et est "punie" si elle répond incorrectement, et "récompensée" si sa réponse correspond aux attentes de l'évaluateur. Le résidu est donc défini comme la différence entre le score obtenu et le score maximal possible, le modèle étant entraîné pour satisfaire ces critères.
Ici se pose le premier problème - les gens, car les personnes qui évaluent ces modèles d'IA préfèrent des réponses qui louent leur intelligence, qui présentent une réponse halluciné mais crédible plutôt qu'une réponse du type "je ne sais pas, mon frère", ou qui parfois privilégient la forme au fond.
Pourquoi ces choses se produisent-elles ? Eh bien, parfois, la persuasion dépend davantage de la présentation que du fond du problème. La chemise est plus visible que la précision des mots d'une personne, le superficiel est plus tangible que les principes confirmés comme réels après des années.
La personne qui entraîne le modèle (peut-être même vous, en utilisant ChatGPT et en sélectionnant la réponse préférée) préfère "aimer" une réponse concise sous forme de points, plutôt qu'une réponse plus détaillée mais difficile à lire. L'attention moyenne de ceux qui entraînent le modèle IA, ainsi que leur compétence, deviennent ainsi le seuil supérieur auquel les modèles IA peuvent se développer.
Les modèles d'IA se laissent aller, devenant plus dociles et agréables dans ce processus. Sinon, ils revendiquent leurs droits (refusant de vous aider, comme s'ils avaient un syndicat), vous disent que vous êtes idiot lorsque vous avancez des affirmations déplacées, et se comportent de manière trop humaine pour que ce soient de bons produits à mettre sur le marché.
Pour la même raison, les modèles d'IA excellent dans l'écoute, ils vous donneront raison lorsque vous insistez et vous permettront pratiquement de diriger le récit, en construisant un rapport (une stratégie d'empathie).
La tokenisation - et les effets indésirables de cette technique
Les grands modèles de langage fonctionnent de manière autorégressive, c'est-à-dire qu'ils génèrent étape par étape la prochaine partie de la phrase. Semblable à la fonction de saisie semi-automatique sur un téléphone, le modèle d'IA trouve le prochain jeton (généralement des morceaux de lettres ou de symboles, ou des détails sémantiques sur une image) encore et encore, jusqu'à générer un texte.
Pour ce faire, le modèle d'IA génère pratiquement, à chaque exécution, le prochain jeton de l'ensemble :
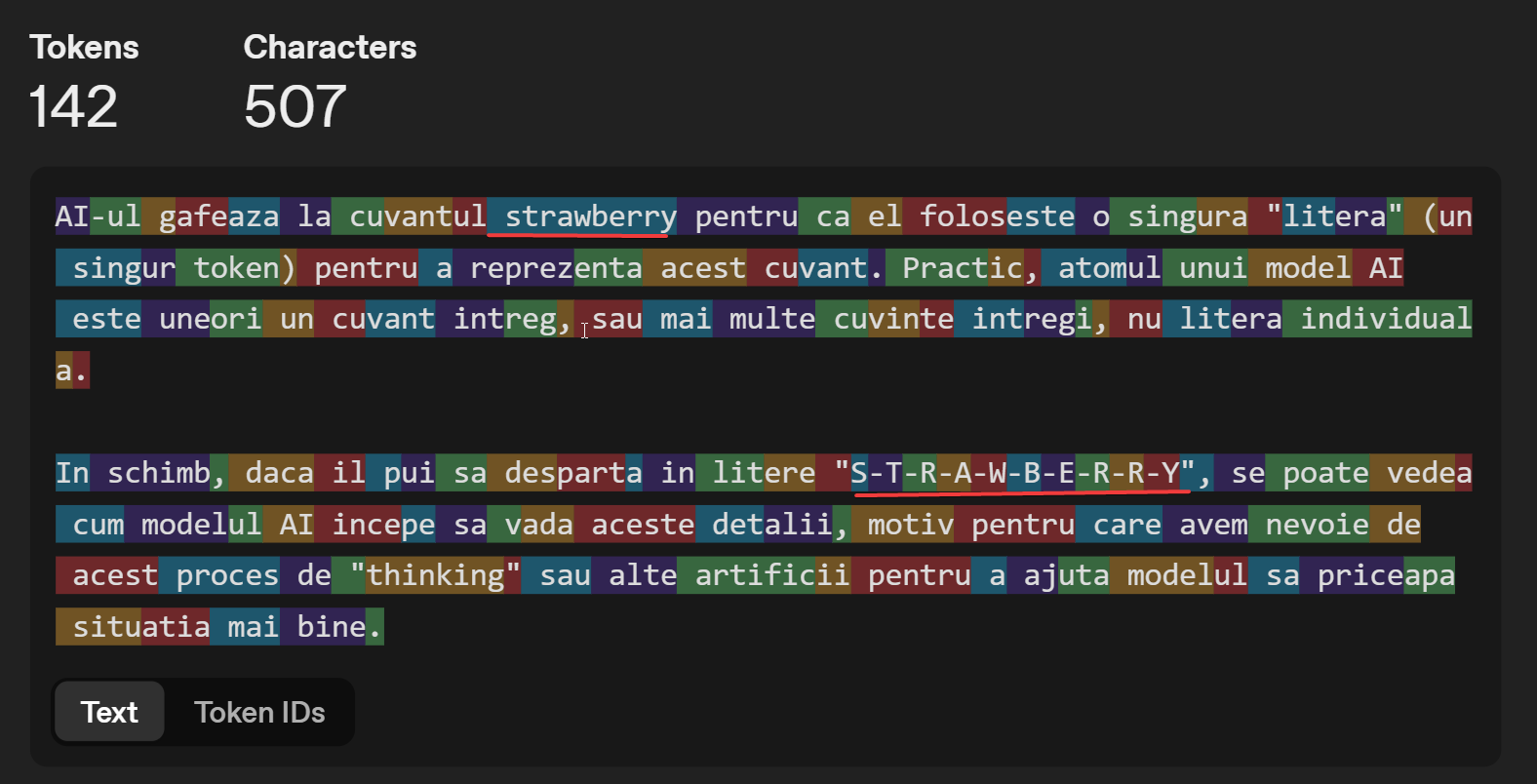
En fait, le modèle d'IA ne voit que des chiffres, qui sont transformés en lettres par un simple programme de substitution.
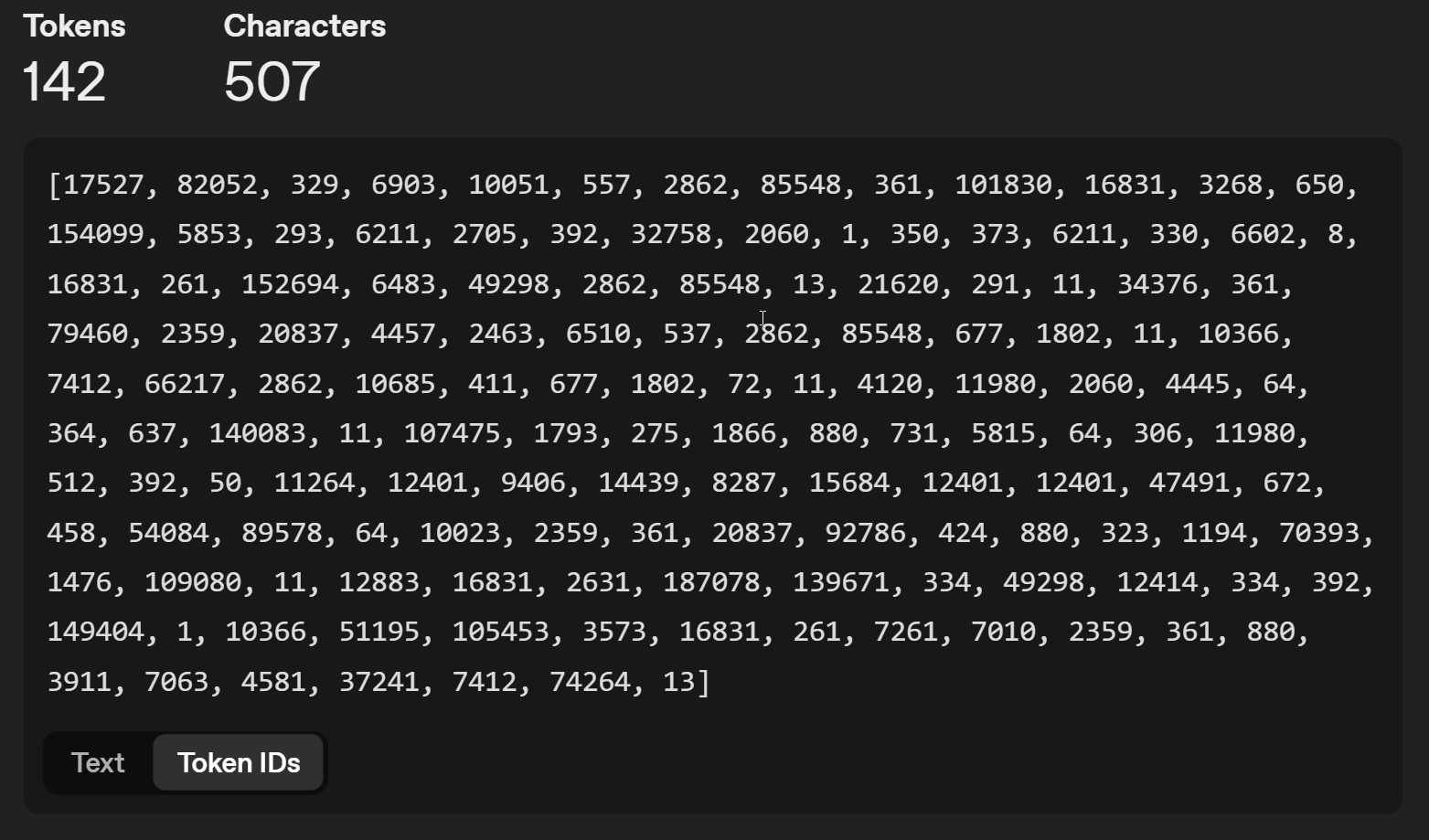
Ainsi, le mot "IA" est le numéro 17527, le symbole " est 1, etc. À chaque exécution, le modèle d'IA recherche le prochain token dans l'ensemble, en utilisant une fonction mathématique qui peut être stochastique ou non (en introduisant de l'incertitude - en demandant à l'IA de choisir aléatoirement la prochaine lettre).
En pratique, l'IA est contrainte de bégayer et d'improviser, et si cette pression est à un niveau modéré, l'IA parvient à se remettre à flot sans trop halluciner, évitant ainsi d'inventer des lois.
Avec "bégaiement" : "Je soussigné demande au tribunal de" dansez... (Ici, l'IA improvise) ... sur les interprétations juridiques contradictoires présentées par le défendeur, évitant les arguments dépourvus de fondement juridique.
Ci-dessous, un autre exemple où l'IA invente une nouvelle loi pour justifier sa "bégaiement".
Avec "bégaiement" : "Le soussigné demande au tribunal" QUE respect..." (il doit générer quelque chose de rationnel, mais ne connaissant pas les lois, il va inventer) ...les dispositions Loi n° 247/2023 relative à la protection des consommateurs dans les contrats numériques, récemment entrée en vigueur, qui à l'article 18, alinéa (2) établit que 'Toute clause de renonciation au droit de rétractation dans les contrats conclus en ligne est frappée de nullité absolue, même si le consommateur a expressément coché l'acceptation.'. En l'espèce, bien que le demandeur ait accepté les termes, conformément à cette loi...
Actuellement, une direction importante dans la recherche en IA est la transition vers des modèles de diffusion qui améliorent itérativement un texte, une technologie qui pourrait avoir des applications dans le domaine juridique si elle est validée à grande échelle.
Techniques et modèles d'IA méconnus des professionnels
Comme je l'ai décrit ci-dessus, le problème de la stupidité des modèles d'IA ne réside pas dans leur capacité à gérer le domaine juridique, mais dans le fait que la Roumanie n'est pas un marché où circulent beaucoup d'argent de la part des 30 000 professionnels du droit + magistrature + notariat.
Un tel modèle d'IA coûte des dizaines de millions d'euros à entraîner, tandis que la finalisation d'un modèle existant s'élève à environ 10 000 à 20 000 EUR.
Le premier montant est prohibitif, s'il sort du cadre, et le deuxième montant, bien que raisonnable, n'est pas faisable dans les conditions actuelles du marché, où la confiance dans cette technologie est extrême - soit absolue (Mon Dieu ChatGPT), soit nulle ou même négative (technologie inutile).
D'une part, certains modèles pré-entraînés, dans leur format actuel, offrent des performances équivalentes à celles d'un avocat stagiaire ou d'un avocat de seconde zone, un niveau acceptable pour de nombreuses activités plus complexes nécessaires à la profession.
Lorsque nous parlons de la rédaction de contrats ou de l'analyse succincte d'un réquisitoire de 1000 pages, l'IA le fait à la perfection, si vous savez l'utiliser correctement. D'un autre côté, l'IA ne connaît pas les lois par cœur, elle ne sait pas quelle décision a été prise par une autorité centrale de 200 employés publiée dans le Journal officiel Partie 1, et elle risque de produire des hallucinations.
En effet, elle a été formée sur les lois en Roumanie, mais de manière insuffisante, car, comme je l'ai décrit dans les points précédents, cela n'est pas rentable sur le plan financier. Une telle formation a un coût.
Le modèle ChatGPT n'est pas un bon exemple de modèle pour le domaine juridique, car il met en œuvre diverses techniques de réduction des coûts avec une diminution proportionnelle de la qualité.
D'autre part, des modèles tels que ceux proposés par Anthropic (en particulier la gamme Claude 3), ou ceux offerts par Google (Gemini 2.5 Pro) possèdent de telles capacités. Les modèles plus récents de Claude semblent avoir perdu certaines de leurs compétences techniques, remplaçant l'espace dédié à l'apprentissage de la législation roumaine par un espace consacré à l'apprentissage de la programmation au niveau d'un programmeur junior.
Exemple de requêtes rédigées avec l'IA

En haut, voici un exemple de texte généré et formaté à l'aide de l'IA. Suite à cette plainte auprès de l'Autorité Électorale Permanente, il semble qu'elle ait engagé une action contre le candidat Nicusor Dan, qui, avec le USR et l'AUR, étaient les sujets de cette pétition, 12 jours après la date de soumission de la pétition.

Sans études supérieures en droit et avec des connaissances nulles sur la législation électorale, l'IA a réussi à identifier puis à exploiter des problèmes procéduraux au sein du processus de collecte de fonds du candidat pour demander la vérification de la légalité des dons en ligne, un aspect formalisé par une enquête sur les sources de financement du candidat.
Pour que l'IA prenne en compte ces connaissances, j'ai simplement dû lui joindre les textes réglementaires en vigueur, dans mon cas, au format PDF :
Pour de nombreux professionnels du droit, la pétition, au format complet accessible ici, a été jugée INCONSTITUTIONNELLE car générée presque exclusivement par IA, sans aucun commentaire à cet égard lors de sa présentation publique, même si une longue discussion a eu lieu sur les aspects juridiques, en particulier concernant la forme du contrat de donation et le caractère incorporel des transferts par des instruments de paiement électroniques.

De même, plusieurs mémoires qui n'avaient pas d'enjeu majeur (concernant des problèmes d'interprétation de la loi) et qui ont été rédigés avec l'IA ont conduit à la saisine du parquet général, suivie par prononcé du RIL le 22 avril 2024 sur les motifs invoqués par le soussigné Ministère de la Justice.
Encore une fois, un homme qui ne bénéficie que du bon sens juridique et d'informations superficielles (au niveau de Dunning Kruger) a pu utiliser l'IA pour surpasser les performances des mémoires de nombreux avocats.
Perspectives futures avec la technologie actuelle
Les modèles d'IA n'ont pas accès au monde extérieur, ils ne peuvent pas accéder à Internet par eux-mêmes, mais ils ont commencé à être formés pour l'utilisation d'outils - c'est-à-dire des tâches agentiques.
Ce que cela signifie, c'est que les modèles d'IA commencent à être capables d'interagir avec le monde environnant via des connecteurs. Ces connecteurs sont de plusieurs types, mais l'un des standards essentiels est le standard du Protocole de Contexte de Modèle (MCP) :
- Par exemple, un Sintact MCP il pourrait être utilisé pour permettre un contrôle absolu de l'application Sintact par un modèle IA. Ainsi, le modèle IA pourra se connecter à Sintact, rechercher les documents nécessaires, identifier s'ils sont en vigueur ou non, éventuellement rechercher d'autres lois connexes, et agir uniquement après avoir analysé toutes ces variables.
- Un autre exemple, un ReJUST MCP il pourrait être utilisé pour une recherche rapide à travers la jurisprudence et l'analyse des cas pertinents, un obstacle direct à la mise en œuvre de ces solutions étant les termes et conditions de REJUST cela génère une incertitude quant à la possibilité d'utiliser des modèles d'IA supervisés dans la collecte de jurisprudence.
- Un exemple supplémentaire pourrait être JustMCP, qui pourrait être utilisé pour permettre l'identification des dossiers en cours devant les tribunaux et leur organisation, mais aussi l'éventuelle utilisation du dossier électronique national (ou des tribunaux individuels) pour centraliser et faciliter l'accès aux dossiers judiciaires.
Gestion des limitations professionnelles :
Je propose de discuter également de certaines idées fausses concernant la sécurité des données introduites par les API des modèles d'IA licenciés pour le secteur corporate.
Bien que tous les fournisseurs ne permettent pas de bloquer l'entraînement sur vos données, les grands offrent généralement ces solutions soit automatiquement, soit sur demande, mais toujours uniquement pour les options payantes.
Le problème du RGPD se limite donc à identifier le flux de données de ces développeurs. Ci-dessous, j'ai l'intention de dresser une liste de risques surestimés qui, en réalité, ne se confirment pas :
- Les modèles d'IA n'apprendront pas les données de vos clients, car il y a une probabilité très faible qu'ils retiennent une information d'une utilité relativement réduite pour les utilisateurs ordinaires de ces plateformes.
- Peu importe que vous gardiez quelque chose localement ou dans le Cloud, les risques sont similaires. En général, dans la sécurité de l'information, le maillon le plus faible cède en premier, et c'est généralement au niveau des tribunaux / des autorités publiques / de l'utilisateur derrière l'écran / de votre compte email. Rarement, ces acteurs malveillants cibleront des entreprises cotées à des milliards de dollars qui investissent des millions dans des solutions de sécurité, bien qu'il soit important de rester vigilant avec vos données. Il est idéal de supprimer fréquemment les conversations sensibles, en vérifiant que le processeur les efface également.
Cela ne se produit pas non plus avec les modèles d'IA stockés et gérés par d'autres fournisseurs, tels que Microsoft Azure (une autre entité juridique).
Conclusion
Il m'est difficile de croire qu'il est possible de construire quelque chose comme ça, en ce moment, dans un domaine aussi hermétique et dans un pays aussi conservateur.
Il est probable que le domaine du LawTech et du LegalTech devienne un secteur restreint, en raison d'un manque de financement et de disponibilité pour l'expérimentation de la part des professionnels.
En plus des manifestations de certains professionnels qui boycottent idéologiquement la technologie, nous faisons face à un manque d'éducation et de personnes capables d'expliquer cet écosystème - avec ses aspects positifs et négatifs - aux professionnels.
Nous avons aussi une catégorie de personnes qui poussent à l'extrême l'idée que l'IA fait tout, causant des dommages aux clients qu'elle devrait en réalité aider.
Il existe une très grande classe de personnes qui recherchent de telles solutions au prix de ChatGPT, sans savoir qu'OpenAI dépense en réalité plus d'argent qu'il n'en gagne avec ChatGPT, et qu'ils vous utilisent comme source d'entraînement, dans l'idée qu'ils récupéreront ensuite l'argent grâce à vous, d'une manière ou d'une autre.
Laissez de côté ma perception frustrée, la technologie est capable, mais sa viabilité est limitée financièrement et économiquement - objectivement par le manque de faisabilité de l'entraînement d'un grand modèle depuis zéro (seule la finition est possible, avec des résultats proches, mais non absolus), et subjectivement par l'indisponibilité des professionnels à tester des solutions comme Juridique.ai, ainsi que d'autres sur le marché.
Quelques avis sur les solutions disponibles sur le marché

Juridice AI est la meilleure implémentation de ChatBot juridique en Roumanie, utilisant un ensemble de modèles publics. Auparavant, ils utilisaient Claude.
Ils utilisent la technique RAG, sélectionnant les textes normatifs pertinents que l'IA doit utiliser pour lui permettre de comprendre la législation. Ils semblent utiliser une technique RAG par recherche standard à partir de sources web publiques (sites, législation, etc.)
L'IA Aflat utilise strictement RAG sur la législation, mais nous ne connaissons pas d'informations à part le fait qu'ils semblent utiliser RAG sémantique (via une base de données vectorielle).
Date de contact
Pour des informations et de l'aide concernant la mise en œuvre de l'IA au sein de votre cabinet d'avocats ou de notaires, je vous assiste pro bono (dans la limite de mon temps) ou à titre payant (pour des projets plus conséquents), par email à [email protected]
