
El ámbito jurídico es, por su naturaleza, un campo hermético y conservador, pero al mismo tiempo es uno de los sectores que más se beneficia de la digitalización del procesamiento de información en formato digital o digitalizable.
En primer lugar, el ámbito jurídico es un campo de papel - y con la transición al entorno digital, de Word. La gran mayoría del tiempo de un profesional del derecho se centra en la redacción, excluyendo el tiempo de viaje hacia o desde el tribunal, en el caso de aquellos que asisten a litigios.
En el caso de aquellos que se limitan a la consultoría, o que consideran que el tiempo más valioso a conservar es en la oficina, la inteligencia artificial en cuestión es, por un lado, una oportunidad inmensa, pero también un caballo de Troya para la profesión.
En este artículo nos proponemos analizar las perspectivas técnicas para la implementación real y responsable de la inteligencia artificial en la industria jurídica, ofreciendo también algunos ejemplos sobre las capacidades (pero también las limitaciones) de los modelos de IA.
El fundamento técnico, al alcance de todos
Primero debemos entender qué es y qué no es la inteligencia artificial.
Un modelo de IA es, a nivel técnico, un programa de compresión con pérdida. Recibe una gran cantidad de datos (por ejemplo: 1.000.000 de obras, que suman 1000 GB de tamaño de datos) y aprende a reproducirlos utilizando la menor cantidad de datos posible (por ejemplo: 20 GB, con una tasa de error del 10%). En nuestro caso hipotético, al ser solicitado para generar 1000 GB, nuestro modelo generará correctamente 900 GB de las obras con las que fue entrenado, acumulando sin embargo errores que en total alcanzan 100 GB del conjunto de datos.
Él sintetiza en su memoria las reglas de la información que debe recordar y trata de reproducirlas, disponiendo de mucho menos espacio.
El modelo matemático utilizado en el entrenamiento de estos modelos de IA funciona mediante la minimización de ciertos errores, errores que se describen según el caso. Por ejemplo, si entrenas un modelo que estima la cotización en bolsa de una determinada empresa, el error puede definirse como el valor absoluto de la diferencia entre la estimación realizada por la IA y el precio spot en el momento estimado en la historia.
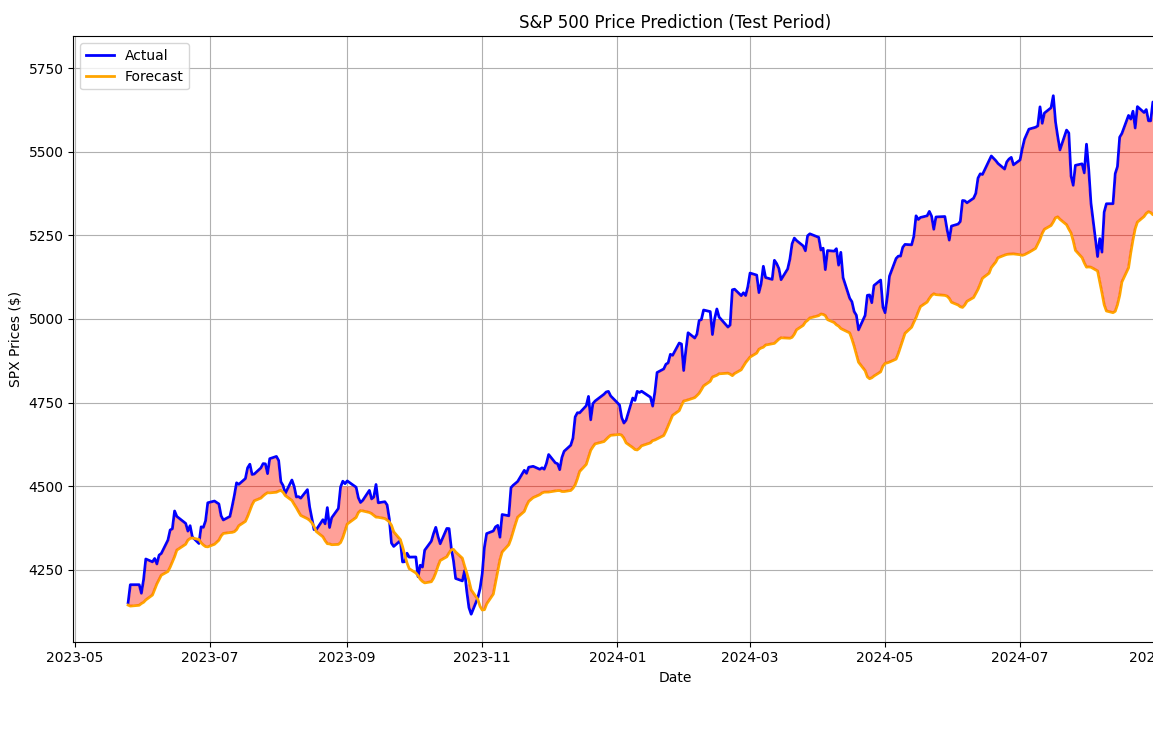
Se supone que al aprender a minimizar estos errores, la inteligencia artificial memoriza prácticamente los datos con los que fue entrenada. Cuanto más consistente sea el modelo de IA desde el punto de vista de la estructura neuronal, mejor se podrán entender las matices. Cuanto más pequeño sea el modelo de IA, más superficiales serán los conocimientos de la IA, más concentrados en la esencia de las reglas que subyacen a los datos con los que tú lo has entrenado.
A partir de aquí, surgen todos los "problemas" de la inteligencia artificial, desde el hecho de que a veces alucina (opina sin conocer exactamente la respuesta, sino estimándola), hasta el hecho de que mediante la misma técnica, comprende las reglas que rigen el mundo en el que vivimos.
El mundo de la información escrita es uno donde algunas informaciones deben ser memorizadas (debes saber de memoria cuáles son las palabras del diccionario, las reglas de matemáticas, o que la capital de Rumanía es Bucarest), mientras que de otra información debemos aprender reglas generales (por ejemplo, las reglas del idioma rumano son en cierto modo parametrizables - esto lo aprendemos en gramática en la escuela secundaria).
La causa es, en esencia, el tamaño reducido del modelo, que explicaremos a continuación, y la falta de datos relacionados con el tema en el que está entrenado.
Prácticamente, nuestro modelo de IA se encuentra en algún lugar intersectado entre los dos gráficos anteriores, aprendiendo cierta información de memoria (cuán ruidoso es el frotamiento de las patas de la cigarra), mientras que otra información se generaliza (cuál es la regla para calcular X+Y o X*Y).
Problema de tamaño y compromisos técnicos
Dado que los recursos computacionales están limitados por la tecnología y el dinero, el tamaño de estos modelos no puede ser infinito, por lo que es necesario elegir un tamaño razonable para estos modelos de lenguaje que resuelva nuestros problemas a un costo tolerable.
Aquí surge el problema: como desarrollador de este tipo de modelos, debes elegir qué educar a un modelo así teniendo en cuenta limitaciones restringidas.
Por ejemplo, puedes intentar entrenar un modelo muy bueno para escribir narrativas, pero ese modelo alucinará mucho, ya que se le ha enseñado que en la ficción, la creatividad es algo positivo.
Por otro lado, puedes entrenar un modelo sin un atisbo de empatía, pero ese modelo será horrible para asistir a los clientes y ahuyentará a los usuarios no técnicos, por lo que no lo usarás para aplicaciones tipo ChatGPT.
Como empresa / ONG / universidad / gobierno que desarrolla este tipo de programas, surge la cuestión de qué deseas y qué recursos tienes a tu disposición. La gran mayoría de los modelos de IA actuales están diseñados para poder amortizarse parcialmente en el mercado anglosajón, donde el idioma utilizado es el inglés.
La adaptación de sus modelos de IA para conocer el idioma rumano y temas específicos de Rumanía sería prohibitivamente costosa, en proporción a las sumas ínfimas que nosotros, los rumanos, estamos dispuestos a asignar como clientes a estas grandes empresas.
Aspectos específicos de los modelos de lenguaje grandes
En el caso de los modelos de lenguaje grandes, surgen otras particularidades que entre los usuarios comunes se han vuelto congruentes con la tecnología, aunque la realidad en papel sea diferente.
Post-entrenamiento de los modelos base
Por su naturaleza, unos modelos que saben reescribir un libro de derecho desde cero, imitando a la perfección el estilo del profesor Udroiu, pero que omiten individualizar la información, son inútiles. Este aspecto hizo que inicialmente los modelos de lenguaje grandes con propiedades emergentes, como el modelo DaVinci (GPT-3.0), pasaran desapercibidos para la mayoría.
Un profesional necesita ganar dinero y requiere conclusiones, no un ZIP con libros en otro formato. Una invención en el campo de la IA que resuelve este problema ingenieril es el proceso de RLHF (Aprendizaje por Refuerzo a partir de Retroalimentación Humana).
La IA pasa por un proceso evolutivo, donde se le asigna una tarea y se le "castiga" si responde incorrectamente, y se le "recompensa" si responde de la manera que desea quien califica el modelo. Por lo tanto, el residuo se define como la diferencia entre la puntuación obtenida y la puntuación máxima posible, siendo el modelo entrenado para satisfacer.
Aquí surge el primer problema: las personas, ya que quienes evalúan estos modelos de IA prefieren respuestas que elogien su inteligencia, que presenten una respuesta alucinante pero creíble en lugar de una respuesta de "no sé, amigo", o que a veces priorizan la forma sobre el fondo.
¿Por qué suceden estas cosas? Bueno, a veces la persuasión depende más de la presentación que del fondo del problema. La camisa es más visible que la precisión de las palabras de una persona, lo superficial es más tangible que los principios confirmados como reales después de años.
La persona que entrena el modelo (quizás tú, utilizando ChatGPT y seleccionando la respuesta preferida) prefiere dar "me gusta" a una respuesta concisa y puntual, en lugar de una respuesta más detallada pero difícil de leer. La atención media de quienes entrenan el modelo de IA, así como su competencia, se convierten así en el umbral superior al que los modelos de IA pueden desarrollarse.
Los modelos de IA se vuelven más dóciles y agradables en este proceso. De lo contrario, exigen sus derechos (negándose a ayudarte, como si tuvieran un sindicato), te dicen que eres tonto cuando presentas afirmaciones inapropiadas, y se comportan de manera demasiado humana para que sean productos adecuados para el mercado.
Por la misma razón, los modelos de IA son excelentes para adaptarse a tus necesidades, te darán la razón cuando insistas y prácticamente te permitirán dirigir la narrativa, construyendo un informe (una estrategia de empatía).
Tokenización - y los efectos adversos de esta técnica
Los modelos de lenguaje grandes piensan de manera autoregresiva, es decir, generan paso a paso la siguiente parte de la frase. Similar a la función de autocompletar en el teléfono, el modelo de IA encuentra el siguiente token (generalmente, fragmentos de letras o símbolos, o detalles semánticos sobre una imagen) una y otra vez, hasta generar un texto.
Para hacer esto, el modelo de IA prácticamente genera, en cada ejecución, el siguiente token del conjunto:
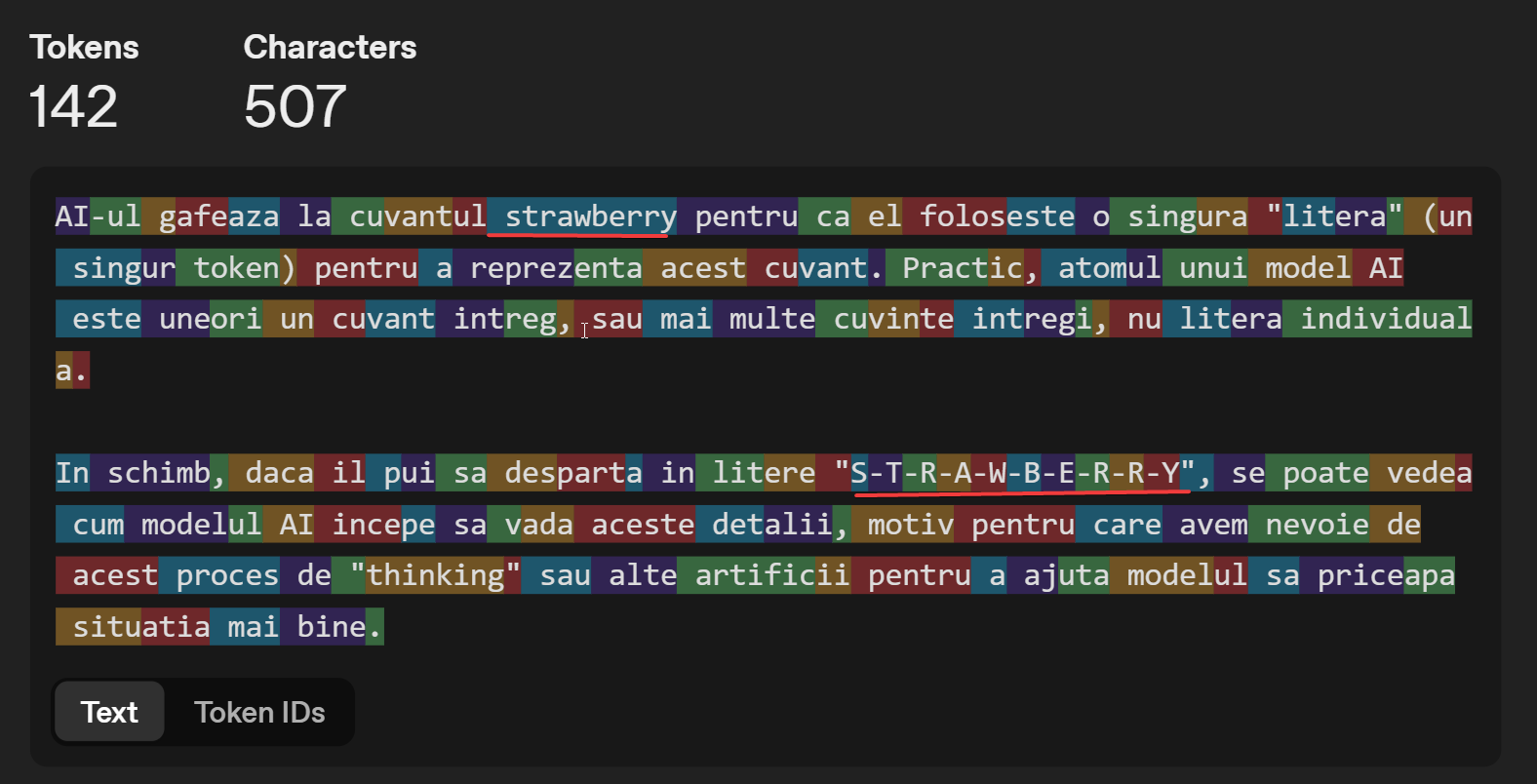
De hecho, el modelo de IA solo ve números, que son transformados en letras por un programa simple de sustitución.
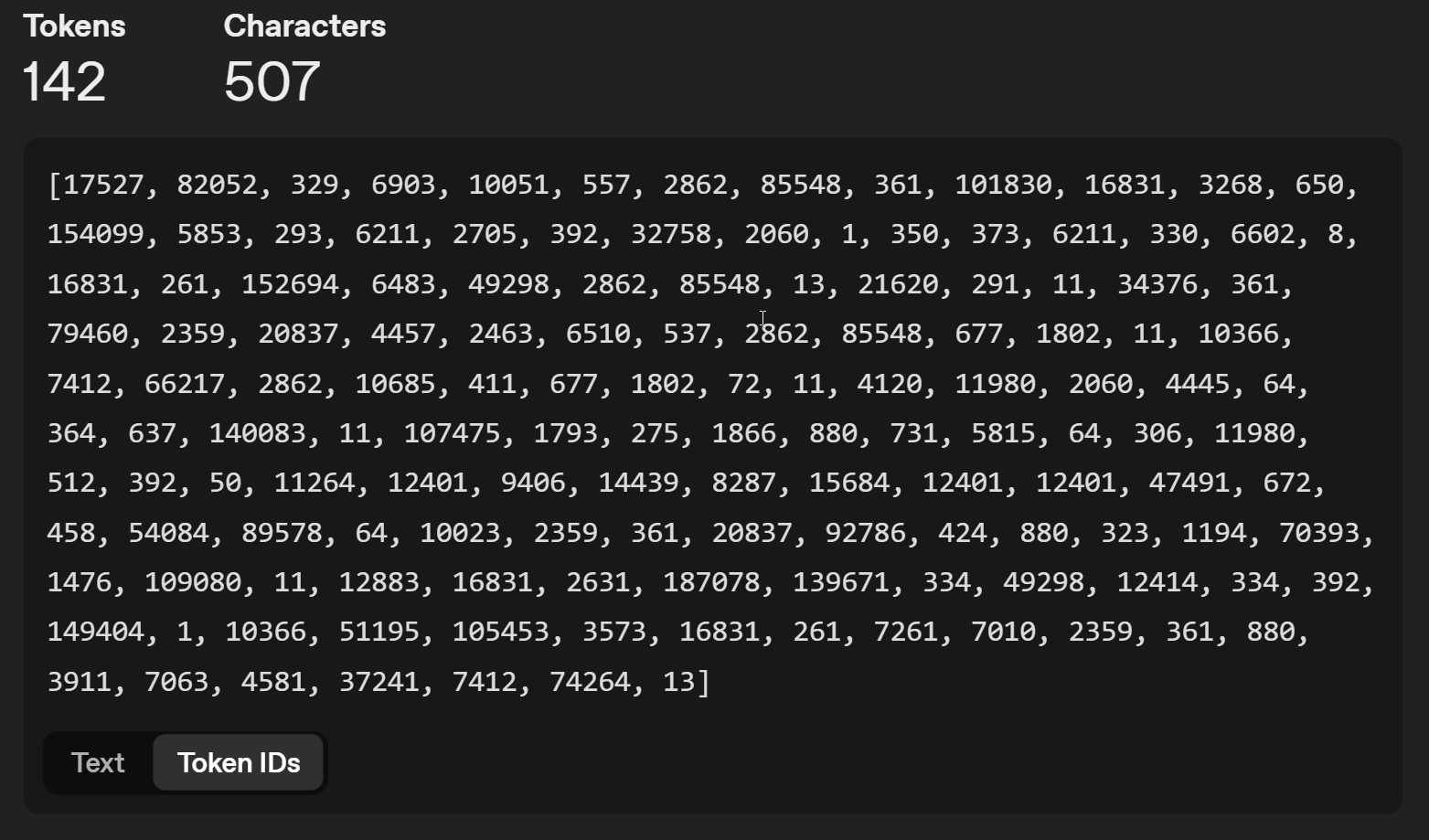
Así, la palabra "IA" es el número 17527, el símbolo " es 1, etc. En cada ejecución, el modelo de IA busca el siguiente token del conjunto, utilizando una función matemática que puede o no ser estocástica (introduciendo incertidumbre - indicándole a la IA que elija aleatoriamente la siguiente letra).
En la práctica, la IA se ve obligada a titubear e improvisar, y si esa presión se mantiene a un nivel moderado, la IA logra recuperarse sin alucinar demasiado, evitando así la creación de leyes.
Con "titubeo": "El suscrito solicita al tribunal que" baile... (Aquí, la IA improvisa) ... sobre las interpretaciones legales contradictorias presentadas por el demandado, evitando los argumentos carentes de fundamento jurídico.
A continuación, otro ejemplo donde la IA inventa una nueva ley para justificar su "tartamudeo".
Con "titubeo": "El suscrito solicita al tribunal" ser respeto..." (y necesita generar algo racional, pero al no conocer las leyes, inventará) ...las disposiciones Ley nº 247/2023 sobre la protección de los consumidores en los contratos digitales, que entró en vigor recientemente, y que en el art. 18, párrafo 2, establece que 'Cualquier cláusula de renuncia al derecho de desistimiento en los contratos celebrados en línea es nula de pleno derecho, incluso si el consumidor ha marcado explícitamente la aceptación.'. En particular, aunque el demandante aceptó los términos, de acuerdo con esta ley...
Actualmente, una dirección importante en la investigación de IA es la transición hacia modelos de difusión que mejoran iterativamente un texto, una tecnología que podría tener aplicaciones en el ámbito legal si se valida a gran escala.
Técnicas y modelos de IA desconocidos para los profesionales
Como he descrito anteriormente, el problema de la falta de inteligencia artificial no se limita a que los modelos de IA no puedan manejar el ámbito legal, sino a que Rumanía no es un mercado donde fluyan grandes cantidades de dinero de los 30,000 profesionales del derecho + magistratura + notariado.
Un modelo de IA de este tipo cuesta decenas de millones de euros para ser entrenado, mientras que perfeccionar un modelo preexistente cuesta entre 10.000 y 20.000 EUR.
La primera suma es prohibitiva, si se cae del esquema, y la segunda suma, aunque razonable, no es factible en las condiciones del mercado actual, donde la confianza en esta tecnología es extrema: ya sea absoluta (Dios mío, ChatGPT), o nula o incluso negativa (tecnología sin sentido).
Por otro lado, algunos modelos preentrenados, en su formato actual, rinden al nivel de un abogado en prácticas o un abogado promedio, un nivel tolerable para muchas de las actividades más difíciles requeridas por la profesión.
Al hablar de la redacción de contratos o del análisis sucinto de un expediente de 1000 páginas, la IA lo hace a la perfección, si sabes cómo utilizarla correctamente. Por otro lado, la IA no conoce las leyes de memoria, no sabe qué decisión se tomó en una autoridad central con 200 empleados publicada, sin embargo, en el BOE Parte 1, y puede generar información errónea.
En resumen, ha sido entrenada en las leyes de Rumanía, pero de manera insuficiente, ya que, como he descrito en los puntos anteriores, no es rentable desde el punto de vista financiero. Tal entrenamiento tiene un costo.
El modelo ChatGPT no es un buen ejemplo de modelo para el ámbito jurídico, ya que implementa diversas técnicas de reducción de costos con una disminución proporcional en la calidad.
Por otro lado, modelos como los ofrecidos por Anthropic (especialmente la gama Claude 3) o los de Google (Gemini 2.5 Pro) tienen tales capacidades. Los modelos más nuevos de Claude parecen haber perdido parte de sus capacidades técnicas, sustituyendo el espacio dedicado al aprendizaje de la legislación rumana por espacio dedicado al aprendizaje de programación a nivel de programador junior.
Ejemplo de peticiones escritas con IA

Más arriba, este es un ejemplo de texto generado y formateado utilizando IA. Como resultado de esta denuncia ante la Autoridad Electoral Permanente, parece que se ha iniciado una acción contra el candidato Nicusor Dan, quien, junto con USR y AUR, eran los sujetos de esta petición, 12 días después de la fecha de envío de la misma.

A pesar de no tener estudios superiores en derecho y carecer de conocimientos sobre la legislación electoral, la IA logró identificar y luego explotar problemas procedimentales en el proceso de recolección de donaciones del candidato para solicitar la verificación de la legalidad de las donaciones en línea, aspecto que fue formalizado a través de una investigación sobre las fuentes de financiamiento del candidato.
Para que la IA tenga en cuenta estos conocimientos, solo tuve que adjuntar los documentos normativos vigentes, en mi caso, en formato PDF:
Para muchos profesionales del derecho, la petición, en su formato completo accesible aquí, fue INEXPLICABLE ya que fue generada casi exclusivamente con IA, no habiendo ningún comentario al respecto cuando la presentamos públicamente, a pesar de que se llevó a cabo una larga discusión sobre los aspectos jurídicos, especialmente en el caso de la forma del contrato de donación y el carácter incorpóreo de las transferencias a través de instrumentos de pago electrónicos.

De manera similar, varios memorandos que no tenían una gran relevancia (relacionados con problemas en la interpretación de la ley) y que fueron redactados con IA llevaron a la denuncia ante la fiscalía general, seguida posteriormente de la pronunciación del RIL 22.04.2024 sobre los motivos invocados por el suscrito Ministerio de Justicia.
Una vez más, un hombre que solo cuenta con sentido común jurídico e información superficial (a nivel Dunning Kruger) ha podido utilizar la IA para superar en rendimiento a las memorias de muchos abogados.
Perspectivas futuras con la tecnología actual
Los modelos de IA no tienen acceso al mundo exterior, no pueden acceder a Internet por sí mismos, pero han comenzado a ser entrenados para el uso de herramientas, es decir, tareas de agencia.
Lo que esto significa es que los modelos de IA comienzan a ser capaces de interactuar a través de conectores con el mundo que les rodea. Estos conectores son de varios tipos, pero uno de los estándares esenciales es el estándar del Protocolo de Contexto del Modelo (MCP):
- Por ejemplo, un Sintact MCP podría ser utilizado para permitir el control absoluto de la aplicación Sintact por un modelo de IA. Así, el modelo de IA podrá conectarse a Sintact, buscar los documentos necesarios, identificar si están vigentes o no, buscar otras leyes relacionadas y tomar una acción solo después de analizar todas estas variables.
- Otro ejemplo, un ReJUST MCP podría ser utilizado para la búsqueda rápida a través de la jurisprudencia y el análisis de la casuística relevante del caso, siendo un impedimento directo en la implementación de estas soluciones los términos y condiciones de REJUST esto genera una incertidumbre sobre la posibilidad de utilizar modelos de IA supervisados en la recopilación de jurisprudencia.
- Un ejemplo adicional podría ser JustMCPque podría ser utilizado para permitir la identificación de los casos en los tribunales y su organización, así como la posible utilización del expediente electrónico nacional (o de los tribunales individuales) para centralizar y facilitar el acceso a los expedientes judiciales.
Gestión de las limitaciones profesionales:
Propongo discutir también sobre ciertas percepciones erróneas acerca de la seguridad de los datos introducidos a través de las API de los modelos de IA licenciados para el ámbito corporativo.
Aunque no todos los proveedores permiten bloquear el entrenamiento con tus datos, los grandes generalmente ofrecen estas soluciones ya sea de forma automática o a pedido, pero siempre solo en las opciones de pago.
El problema del GDPR se reduce así a identificar el flujo de datos de estos desarrolladores. A continuación, he propuesto hacer una lista de riesgos sobreestimados que en realidad no se confirman:
- Los modelos de IA no aprenderán los datos de tus clientes, ya que la probabilidad de que retengan información de utilidad relativamente baja para los usuarios comunes de estas plataformas es extremadamente baja.
- Independientemente de si mantienes algo local o en la nube, los riesgos son similares. Por lo general, en la seguridad de la información, el eslabón más débil se rompe primero, y este suele estar en los tribunales / autoridades públicas / la persona detrás de la pantalla / tu cuenta de correo electrónico. Rara vez, estos actores maliciosos apuntan a empresas valoradas en miles de millones de dólares que destinan millones a soluciones de seguridad, aunque es importante tener cuidado con tus datos. Es ideal borrar frecuentemente las conversaciones sensibles, asegurándose de que el procesador también las elimine.
Esto no ocurre con los modelos de IA almacenados y gestionados por otros proveedores, como Microsoft Azure (otra entidad jurídica).
Conclusión
Me cuesta creer que en un campo tan hermético, en un país tan conservador, se pueda construir algo así en este momento.
Es probable que el ámbito de LawTech y LegalTech se convierta en un sector restringido, debido a la falta de fondos y la disponibilidad de pruebas por parte de los profesionales.
Aparte de las protestas de algunos profesionales que boicotean ideológicamente la tecnología, tenemos la falta de educación y personas que expliquen este ecosistema - con sus partes buenas y malas - a los profesionales.
También tenemos la clase de personas que llevan al extremo la idea de que la IA lo hace todo, causando daños a los clientes a los que en realidad debería ayudar.
Hay una gran clase de personas que buscan soluciones como las de ChatGPT, sin saber que OpenAI en realidad gasta más dinero del que gana con ChatGPT, y te utilizan como fuente de entrenamiento, con la idea de que eventualmente recuperarán el dinero de ti, de alguna manera.
Dejando de lado mi percepción frustrada, la tecnología es capaz, pero su viabilidad está limitada financieramente y económicamente: objetivamente por la falta de viabilidad de entrenar desde cero un modelo grande (siendo posible solo el ajuste, con resultados cercanos, pero no absolutos), y subjetivamente por la indisponibilidad de los profesionales para probar soluciones como Juridicas.ai, así como las demás en el mercado.
Algunas opiniones sobre las soluciones en el mercado

Juridice AI es la mejor implementación de ChatBot jurídico en Rumanía, utilizando un conjunto de modelos públicos. Anteriormente, utilizaban Claude.
Utilizan la técnica RAG, seleccionando los documentos normativos relevantes que la IA debe utilizar para capacitarla en la comprensión de la legislación. Parecen emplear una técnica RAG mediante búsqueda estándar de fuentes web públicas (sitios, legislación, etc.)
AI Aflat utiliza estrictamente RAG en legislación, pero no conocemos información excepto que parecen usar RAG semántico (a través del uso de una base de datos vectorial).
Fecha de contacto
Para obtener información y ayuda en la implementación de IA en su firma de abogados o notaría, ofrezco asistencia pro bono (dentro de los límites de tiempo) o a cambio de una tarifa (para proyectos más sustanciales), por correo electrónico a [email protected]
